- Research
- Open access
- Published:
Network-theoretic modeling of complex activity using UK online sex advertisements
Applied Network Science volume 5, Article number: 30 (2020)
Abstract
Online sex has become a fast-growing business in both developing and developed network, with advertisements of (not necessarily unique) individuals numbering in the hundreds of millions across different Web portals. One such major hub of sex advertisement activity, before it was shut down by US federal agencies, was backpage.com. The backpage.com website was a classifieds-advertising portal that had become the largest marketplace for buying and selling sex by the time that federal law enforcement agencies seized it in April 2018. Since then, investigations have been actively underway. However, the data (which has recently been made available to us for research on UK Backpage) also offers valuable insights into the nature of the online sex business, including complex properties that can be best studied using network science. One of the challenges, however, is a rigorous modeling of the data as a network, since the primary data are web advertisements and metadata (backend database) on accounts that posted that ad. In this article, we conduct an empirical study of an important sample of the online sex marketplace using UK backpage, including presenting a methodology for constructing simple ‘activity networks’ that define some notion of real-world collaboration or connection between two entities (in our case, at the level of ad-posting accounts) and then studying the properties of these networks. We gather a set of insights into a domain that has not been studied at scale, let alone a national level, but that is continuing to be a growing social problem for many countries.
Introduction
The rise of the Web has had an unfortunate side effect, namely the emergence of illicit domains and marketplaces. In this article, we focus on the sex marketplace, where sex providers advertise their services online for potential customers to find and solicit (Edelman and Stemler 2019). Unlike many online transactions of an illicit nature, such as drugs or even weapons, the online sex marketplace is an interesting one because it has an outsize presence both on the Dark Web and the normal Web (Hultgren et al. 2016; Alvari et al. 2016). On the normal Web, such advertisements can (and to a great extent, are) accessed by non-technical users on a normal website such as a classified-ads portal like backpage.com. On the surface, backpage.com did not look like a website that advertised illicit services, since it contained advertisements for many everyday items and agendas, including furniture, rentals and events (Fig. 1).

The backpage.com home page, as it used to look before the entire website was shut down by federal agencies
Even before the shutdown, there was controversy (both legally and in the press) over the ‘adult’ section that included adult services such as escorts. This section became the subject of several agencies, including the FBI and the US Department of Justice, over accusations that the website knowingly allowed and encouraged users to post ads related to prostitution and human trafficking, especially involving minors, and took steps to obfuscate these activities purposefully. At the time of writing, the former CEO has pleaded guilty to charges of facilitating prostitution and money launderingFootnote 1. He has also acknowledged that many of the advertisements on Backpage were advertisements for prostitution, a finding that we have verified empirically by sampling many ads and looking at their content. Since the website has been shut downFootnote 2, its data is with law enforcement. The data spans many countries and languages, though the US is the dominant market.
In this article, we use some of this data to study the UK market over a period of several recent years, including the complex nature of activity in this domain. We took the corpus of ads and accounts spanning the UK market and cleaned the data (as described subsequently) to focus on the subset where sexual services are being advertised with high probability. Unlike previous studies, which have been small scaleFootnote 3 and/or involved data that was scraped online and then subjected to automatic procedures for extraction of information such as phone numbers, we are able to work at the level of accounts, which are formal entities representing a set of ads, since we know exactly which account the ad was posted from. This data allows us to sidetrack a nebulous problem that has often been faced in this community, namely how to determine when a set of ads is referring to the same individual or is otherwise cohesive for analytical purposes. We then define and model activity networks from this data. Activity in this context is defined as an action taken by a sex provider to post an ad from an account registered with backpage.com. Since such ads are associated with an IP address and phone number(s), it becomes possible to model such activity networks by linking together accounts that are related in the real world, either because accounts were being created from a common IP address or because common phone numbers were extracted from the metadata of ads that were posted from different accounts. Activity networks are important because, in the sexual services domain, many providers do not act alone and could be connected together in small (or in rare cases, large) groups. Such groups (also called ringsSmith and Smith (2011); Jones (2010)) can sometimes be indicative of human trafficking or organized crime and subject to further investigation by law enforcement. What is unknown at scale is: how many such ‘groups’ are present and what is the degree of connectivity among them? What ‘structural’ observations and conclusions can we note about the domain?
We describe our methodology in detail in the next few sections, followed by a network-theoretic presentation and analysis of the results that seek to answer some of the questions posed above. Specific contributions are described below.
Contributions
Our primary contribution in this article is to formulate a research agenda around deriving insights into online sex marketplaces by ingesting a raw database containing details on sex advertisements posted in a certain time period (and within the confines of a national jurisdiction, namely the United Kingdom), and using network science to systematically study and profile the data. A direct construction of social networks from this data is not possible since we have not observed direct social connections in the data. Instead, we propose to define and study proxy ‘activity’ networks as a way of deriving insights into the underlying dynamics of UK online sex markets. Specific contributions include:
-
1.
We propose to build ‘activity’ rather than ‘social’ networks to study the phenomenon of online sex advertisements within a rare setting that is not subject to data collection biases. While we provided some intuition behind the definition of activity in the previous section, a more formal treatment will be subsequently provided when we describe the construction of the networks. We note that thus far, such biases (mainly introduced due to Web crawling systems), as well as limitations in data collection, have prevented such a study except at the smallest scales (as we describe in the Related Work).
-
2.
We study and compare the different activity networks using network science, and derive interesting empirical insights that could potentially guide both policy and investigation. For example, while we obtain evidence of the power law when mapping a particular activity network’s empirical degree distribution, we also find significant positive assortativity, which suggests a ‘rich club effect’ rather than preferential attachment.
-
3.
We present case studies around two highly active accounts, one of which was revealed due to the results of our activity network analysis, and make some qualitative observations based on the data we sampled from those accounts. We argue through the case studies that high-degree accounts in the activity network represent qualitatively more interesting and suspicious behavior than another standard measure of account activity (the number of ads posted by an account). Ultimately, our findings suggest that network theory could be a useful computational paradigm for policy experts and law enforcement alike in interpreting certain kinds of activity in the online sex domain in their proper empirical context, and also in more effectively finding traces of highly suspicious or deviant activity (such as sex trafficking and/or human smuggling) compared to simple random sampling of accounts.
Related work
Studying the structural properties of online sex markets in a national context using a paradigm such as network science is necessarily interdisciplinary. Our work has been influenced both by the social science literature on the sex trade (and human trafficking) as well as Artificial Intelligence tools designed specifically for such domains, especially due to national research programs such as DARPA MEMEX in the United States (Fox-Brewster 2015). Beyond sex markets, there have been considerable developments in both network science and in fraud analytics in the cyber domain. We attempt to provide a broad, though necessarily non-exhaustive, overview of several categories of related work in each of the sections below.
Online sex markets and artificial intelligence
Due to the advent of the Web, and the low cost of entry for both website publishers and consumers of content in Western countries, there has been significant proliferation of online illicit activity, including online sex advertisements, illicit massage parlors and even human trafficking. This is the most novel aspect of this work, since (despite all the illicit activity happening online) surprisingly little can be said with certainty about the online sex domain or the disturbing growth of its impact. By some estimates, human trafficking alone is a multi-billion dollar industry globally; unfortunately, due to socio-technical causes, it was not well-studied using computational science methods till quite recently (Hultgren et al. 2016; Alvari et al. 2016). Systems that can assists NGOs and law enforcement exist, of course; for example, in our group, we built the DIG (Domain-specific Insight Graphs) system (Szekely et al. 2015) to help law enforcement selectively ferret out ads that are indicative of human trafficking. Other systems include DeepDive and FlagIt, and use a combination of database and Artificial Intelligence technologies (Kejriwal et al. 2017; Rabbany et al. 2018; Alvari et al. 2017; Burbano and Hernandez-Alvarez 2017). For example, Rabbany et al. (2018) explore methods for active search of connections in order to build cases and combat human trafficking. Similarly, FlagIt attempts to semi-automatically mine indicators of human trafficking (which include movement, advertisement of multiple girls etc.) (Kejriwal et al. 2017). In general, building good ‘entity-centric search’ tools for analyzing and mining such ‘heterogeneous’ data and concepts on the Web (not necessarily coming from the sex trade or other unusual domains) have occupied a significant niche in the AI and Information Retrieval literature. A representative (and non-exhaustive) set of references from entity-centric search and data integration literature includes (Hogan et al. 2007; Lin et al. 2012; Saleiro et al. 2016; Tonon et al. 2012), and Doan et al. (2012).
Other relevant work include Fox-Brewster (2015) (providing details on the DARPA MEMEX program, which took a closer look at human trafficking and funded several works cited above), Kejriwal and Szekely (2017) (covering information extraction in illicit Web domains; in particular, human trafficking), Edelman and Stemler (2019) (which considers federal limitations on regulating online marketplaces), Harrendorf et al. (2010) (which provides international statistics on crime and justice), Tong et al. (2017) (which seeks to semi-automatically detect human trafficking in Web ads through multimodal deep learning), Burbano and Hernandez-Alvarez (2017) (which, similar to the work in Tong et al. (2017), attempts to identify human trafficking patterns online through computational means), Kejriwal and Kapoor (2019) (which also uses network science, but as a means for understanding noise in information extracted from sex advertisements, rather than for analysis of the underlying social system itself) and Kapoor et al. (2017) (which uses Artificial Intelligence techniques to correctly extract and identify locations in sex advertisements).
The work in this paper is an empirical study, rather than a predictive or prescriptive model (unlike many of the systems cited above). Model-based systems are useful in applied settings, such as in helping gather evidence to successfully prosecute a trafficker, but cannot be used for empirical studies due to lack of data and inherent bias in model training. For example, almost all of the systems described above are specifically designed to detect human trafficking activity. In contrast, we do not aim to solve such a difficult and ill-defined predictive problem; instead, we present a study of the broader domain but within a relatively restricted legal and political context (i.e. limited to UK jurisprudence). As we describe in subsequent sections, our data is from a single high-quality source (Backpage) that presents a broad view of the domain, spanning multiple regions and cities in the UK. There is also precedent for using Backpage for studies of this nature e.g., one recent study specifically investigated human trafficking from the lens of bitcoin transactions on Backpage (Portnoff et al. 2017).
Social science studies on the sex trade and human trafficking
The vast majority of academic literature on the sex trade and human trafficking has not been computational, but is still of great importance in placing the findings of this article in context. We note here some selected pieces of social science and policy work that have focused on the sex trade, and human trafficking, in particular. An excellent literature review of sex trafficking and sex work was provided by George et al. (2010). There is also a special journal published by Taylor and Francis on human traffickingFootnote 4, which we recommend for the reader specifically interested in that aspect of the sex trade. Some articles in the journal are country-specific, similar to this work (which focuses on the UK); e.g., in a very recent article, Baglay (2020) discusses access to compensation for trafficked individuals in Canada, while Chantavanich (2020) discusses Thailand’s challenges in implementing anti-trafficking legislation. In a similar vein, Shuai and Liu discuss human trafficking in China (Shuai and Liu 2020). As we stated earlier, computational or even model-based studies on the properties of online sex markets (beyond using AI for detecting signals of human trafficking semi-automatically) have been very rare; much of the relevant research has already been cited in the section above on online sex markets. For understanding the links between trafficking and ordinary prostitution, we recommend the handbook by O’Connor and Healy (2006). None of these uses a framework such as network science to map or gain empirical insight into the structural properties of online sex markets, particularly in developed countries where potential customers often find sex providers through digital advertising such as enabled by portals like Backpage. For more details on measuring human trafficking, we recommend the work by Savona and Stefanizzi (2007), as well as the more recent work by Farrell and de Vries (2020).
Some lines of work consider the impact (sometimes unintended and unfortunate) of interventions of legal and political bodies on human trafficking. For example, Smith and Smith studied the unintended effects of United Nations intervention on human trafficking (Smith and Smith 2011). Jones considered the ‘conscious neglect’ of men who have been trafficked, since much of the work tends to focus on women (Jones 2010). In the research herein, no such distinction is made; we consider the full UK Backpage corpus, which includes both women and men (though to a far less extent owing to the fact that a majority of sex providers are women), in our studies. Another study presented methods on estimating online sex customers (hence, it was focused on the demand, rather than the supply, side of the sex business) (Roe-Sepowitz et al. 2016). For a broader understanding of sex work in the digital era, we recommend the synthesis in Jones (2015). Other related work on the market for prostitution services includes the paper by Della Giusta et al. (2009), as well as the sociological study in Adriaenssens and Hendrickx (2012) wherein the authors account for unsafe sexual practices in sex (i.e. prostitution) markets.
Fraud and other illicit activities
Several pieces of research have sought to focus on the emergence of cyber activity as a means of facilitating human trafficking and other such illicit activities. We cite Greiman and Bain (2013) as an important advance in this regard.
Concerning escorts and sex markets in particular, there has also been some limited study on information and signaling in such ‘illegal’ markets; e.g., Logan and Shah (2013) and Capiola et al. (2014) are both relevant in this regard, as is the book by Sanders (2013). The honesty of sex workers, even about such matters as their sexual orientation and age, is not well understood. Some dishonesty is evident even in our dataset, since the same sex worker (identifiable using account and phone number metadata) often changes names across advertisements, or uses obfuscated names and signals (one of our two case studies illustrates the difficulty of studying this without ground truth data). Language use in advertisements can also be irregular and complex; Tyler provides some details in a book on male sex work (Tyler 2014).
Many other illicit activities tend to be present on the Dark Web, rather than the Open Web that is accessible via URLs using a Web browser (Finklea 2015). The Dark Web typically refers to the part of the Internet that is not indexed by search engines, and usually requires ‘anonymizing’ browsers like Tor to access. However, Backpage was a website that was exclusively available on the Open Web; in fact, because it was like a ‘yellow pages’ portal, people would post (and respond to) ads that had nothing to do with the sex trade, such as finding roommates or selling furniture. That being said, exploring, analyzing and mining the Dark Web is also an important problem for which network science could be employed as future work (Chen 2011). Recent work on this across domains such as terror, cryptocurrency, cybercrime, drugs and weapons has been quite illuminating (Hurlburt 2017; Weimann 2016; Lee et al. 2019; Zulkarnine et al. 2016; Kruithof et al. 2016; Martin 2014; Rhumorbarbe et al. 2018; Bradbury 2014), though work specifically looking at sex markets and human trafficking has been rare (Rhodes 2016; Williams 2013; Haasz 2015).
Network science
Network science has been a successful framework for modeling and studying complex systems with interactions and other structural properties (Barabási and et al. 2016). Established and well-known cases of such models have arisen in the study of protein-protein interactions, citations and social interactions (Gavin et al. 2002; Hummon and Dereian 1989; Borgatti et al. 2009). Recent research has led to many exciting advances in the construction and study of complex networks, especially from ‘Big Data’. For example, Chen and Redner study the community structure of the physical review citation network from the mid-1890s to 2007 (Chen and Redner 2010). Other domain-specific examples include the study of patent citation networks in nanotechnology (Li et al. 2007) and the creation and influence of citation distortions (Greenberg 2009). A good synthesis on social network analysis may be found in multiple works, including the seminal work by Wasserman and Faust (1994), Borgatti et al. (2009) and the more recent work by Knoke and Yang (2008). Privacy in the context of mining social network data has also been well studied (Kleinberg 2007). There has also been considerable work in recent times on more advanced networks, such as signed networks (Leskovec et al. 2010), as well as the intersection of network science and other fields like biology, crowdsourcing and economics (Easley et al. 2010; Wernicke and Rasche 2006; Berger and Iyengar 2009; Schreiber and Schwöbbermeyer 2005). Nevertheless, social networks and sociology continue to influence, and be influenced by, network science, going back to at least the time of Moreno (1946).
However, due to the high barriers of acquiring unbiased data at scale in the online sex advertisement domain, applied network analytics has never been applied at a national level to the study of such a system. It is not even clear how to model raw data, if available, as a network. Our data is unbiased because it was not crawled or otherwise subject to some kind of sampling bias (whether known or unknown), but was given to us as a full dump by law enforcement. Our contributions are dual; we show both how to model the data as ‘activity networks’, rather than social networks (which have a controversial meaning in this domain), as well as derive a range of important insights from the data. We show definitive evidence (via a case study of two accounts) that network science can add value to the study of such data in this domain, as opposed to studies based only on aggregate statistics or sampling.
Data
Before it was shut down in the first half of 2018, backpage.com was a thriving ‘classified yellow-pages’ website that operated globally and was a direct rival to other similar websites like craigslist.com. However, backpage.com also had significant online sex advertisement activity on its portals, usually under the online dating and massage sections. In a case that is still ongoing, US federal agencies shut down the website and seized its servers and data. For our studies, we were given limited access to UK Backpage data. Out of consideration for the data providers and the sensitive nature of the research, we do not reveal identifiers and our analysis is restricted to empirical studies at the level of the country rather than very specific regions and locales.
There is a significant amount of machine learning and predictive analytics currently underway with regard to this data. However, the primary focus of this article is on constructing and describing the activity networks; hence, we do not describe any of the machine learning results or methodologies here. For the network analysis, we mainly relied on the Python NetworkX packageFootnote 5. The methodology for handling and preprocessing the raw data over which the networks were constructed is described below.
Data preprocessing and statistical profiling
The raw database files, acquired through our partners in federal agencies and law enforcement, comprise of 129 mySQL database files, many of which were not necessary for the study herein (since they did not contain any content or metadata that we used in the study). Furthermore, even among the databases that were useful (which were mainly user account data and the advertisement database itself), there were large subsets that had nothing to do with online sex advertising, and were just ‘ordinary’ ads such as listings for furniture or jewelry. Hence, significant preprocessing and filtering was necessary to isolate and join those parts of the database that are directly relevant to online sex. In preprocessing the raw data, we note that we erred on the side of precision rather than recall to ensure that our findings are of high quality. Empirically, any network built (even perfectly) from such a corpus of ads will always be incomplete, since there is no one online portal that has all online sex advertisers listed on it. Furthermore, there are providers who may never list online but who are connected to individuals who are listed online. Just like online social networks therefore, we do not observe the complete activity record for an individual or their interactions, but the hope is that, with high quality data preprocessing and network construction, we observe a representative sample of the true underlying (and unknown) network. We also consider data that is fairly recent still at the time of writing; a distribution is shown in Fig. 2.

A distribution of number of ads over time in the dataset used in this study. The activity we are profiling in this article has all occurred over a maximal period of three years
An important preprocessing step is to separate adult-oriented ads soliciting sexual services from non-adult ads, as well as adult ads that are not soliciting services of an illicit nature. Empirical observation and conversations with domain experts revealed that a high-precision method for obtaining this subset of ads was a two-step approach. In the first step, we removed all ads that had a value of ‘0’ in the age field, which is a backend metadata field that has to be (compulsorily) filled in when posting a Backpage ad. The distribution of remaining ads (i.e. with non-zero ages) is revealed in Fig. 3. While there are a non-trivial number of ads that have listed an age beyond the range of 80 or even 100, our analysis has shown that this just a practical way for the publisher of the ad to indicate non-availability or applicability, either because they are trying to obfuscate the true age, or because they may be advertising multiple women (especially if they are massage parlors, and do not want to list a single age). It is important to note that, because age is a metadata attribute, potential customers looking at the webpage would not be able to view (or search on) this attribute. It was purely designed for Backpage’s record keeping purposes. Hence, this attribute and its distribution of values should not be seen as a true distribution of ages of sex providers advertising through Backpage.

A distribution of ads with non-zero ages
In investigative settings, however, the distribution is important. Precisely because the ads that list a ‘high’ (or even 0) value for the age metadata attribute are associated with such ‘group’ behavior (such as massage parlors or multiple girls advertising together), they are interesting for investigations and studies specifically focused on uncovering coordinated group activity. In some cases, such cases are correlated with trafficking, as covered in the occasional press articleFootnote 6. In the future, with improved accuracy, Natural Language Processing (NLP) technologies could be applied to such subsets of the data to specifically study the properties and emergence of such groups.
Furthermore, as a ‘litmus’ test, we plot (in Fig. 4) the statistical distribution of remaining ads based on their Backpage category (a high-quality field, since it determines where the ad would get posted in the portal, which in turn drove hits). We find that the non-zero age pruning step left ads that are primarily adult-oriented, and even among the adult-oriented categories, the most common category by far was ‘escort’, which is particularly popular for soliciting prostitution and a dominant kind of service (e.g., compared to illicit massage parlors) in the online sex advertisement business in terms of the number of providers offering it. Samples of ads showed (without any exceptions) that the remaining ads were indeed sex-related. We decided to retain all the ads shown in the distribution.

A distribution of non-zero age ads, broken down by category. The label corresponding to the bar is aligned with its left limit e.g., the first bar refers to ‘escorts’ (with an ad count slightly greater than 140,000).
An important and privileged piece of information that is only available at the backend (of backpage.com website infrastructure), and that made much of this study possible, is an ‘account’ ID for each advertisement. Account IDs are associated with user accounts, and are used for paying for the ad, among other things. Advertisements with the same account ID were posted from the same account. Since each account typically posts many ads over its lifetime, and since more than one individual is usually advertised from the same account, it is difficult to ‘automatically’ cluster ads into coherent accounts. This step proved to be unnecessary for us, since we were able to tie each ad to the account that posted it, made possible by each ad’s metadata containing its account ID, which means it can be linked to the account table using a foreign key-like relationship. The distribution of the number of ads posted per account is illustrated in Fig. 5, and is roughly power-law.

A distribution of account sizes in terms of number of ads posted by that account
Profiles of activity networks
Using the account ID information, we were able to construct well-defined ‘activity networks’ where the accounts are nodes in the network. Concerning edges, we considered three different kinds of activity that linked together accounts in the real world. We describe the semantics of these edges shortly. However, one important point to note is that accounts are not the same as ‘individuals’. The reason is that there is a many-many relationship between both ads and individuals (an ad could be advertising multiple individuals, though it is not as common as single-individual advertisements, and an individual usually advertises several times, leading to multiple ads per individual), as well as accounts and individualsFootnote 7 In fact, there is no foolproof way (even for subject matter experts) of ascertaining individuals from either crawled webpages or from the backend without a field investigation. Hence, our findings should not be taken to be a commentary on individual activity. Rather an account should be interpreted as an important unit in itself, since it is directly observable, can be traced back (at least in theory) to an account creator, and in several cases (particularly relevant to coordinated and/or trafficking behavior), the account creator is not the same as the person whose services are being advertised. In the case of ‘human trafficking rings’ (organized groups that buy, sell and trade in human beings, primarily for illegal labor and/or sexFootnote 8) and massage parlors, the creator of the account can be thought of as the ringleader who has control of the account and is paying for it, using it to advertise (and derive profit from) the individuals in the ring who are, whether willingly or not, offering sex services.
For largely similar reasons, the activity in the activity networks that we describe below should not be thought about as being necessarily social in nature. Even when we define the activity by linking two accounts where at least one common phone number was extracted from ads posted from these accounts (a strong signal, considering phones are still the primary mode of communication in the online sex domain), it may be that the activity arises either because an individual previously posting an ad from one account (which itself could be an ‘organizational’ or group account) has now moved to a different account or group (the equivalent of switching jobs in this industry), or due to both accounts being associated with the same group. Hence, edges should not be thought of in the same vein as ‘friendship’ or other such relationships common in more traditional social networks.
Construction of activity networks (ANs): phone, IP and IP prefix
First, we constructed phone activity networks using phone numbers that we extracted from a field called searchblob that is not visible to the person looking at the webpage (when it was live), but that was used at the backend for improving services such as search. The searchblob contains several important keywords, including (usually) the phone number present in the ad for contacting the sex service provider. We were able to extract these phone numbers using regular expressions on the searchblob. Phone number extraction from the actual visible webpage is an extremely difficult problem, and an active area of Artificial Intelligence, due to obfuscation and creative use of tokens and numbers by the writers of the ads (Kejriwal and Kapoor 2019). For example, an advertiser may obfuscate a phone number in the main text by replacing 0 with the letter o, introducing emoticons in the middle of the number, translating some numbers to their word equivalents (and even misspell the word, e.g., ‘Niiine’ instead of ‘nine’ to make the automatic detection task even more challenging, if even possible with current technology), among other steps. However, because the searchblob is well-structured and non-obfuscated, we were able to construct a high-precision extractor for phone numbers within the searchblob. In almost all cases that we sampled for assessing the quality of this procedure, we found that if a phone number occurred in the main text of an ad (regardless of whether it was obfuscated or not), it also occurred in the searchblob and we were able to extract it correctly using our regular expressions.
Next, we construct two other ‘baseline’ networks to compare against the phone activity network in terms of profiling and network metrics. The second activity network, called the IP activity network, uses an ad’s IP address (e.g., 66.171.193.9), which is the outward facing IP from which the ad was posted. The network is constructed in a similar way as the phone AN; if two accounts have at least one ad each that share an IP address, we create an edge in the IP activity network between the two account nodes. Unfortunately, this is a weaker (and less precise) method for defining activity compared to phones, reason being that if accounts are created to be untraceable to an individual’s IP (as they very well might have been, to minimize chances of being caught in a possible investigation) by using a public computer or a VPN, then we may end up linking accounts that should not be linked. Another broader way of defining shared IP activity is by not using the full IP, but its prefix (e.g., the IP prefix for 66.171.193.9 is 66.171.193). This is a much ‘noisier’ activity network, and may even be meaningless in the real world, but is a useful baseline for comparing to the phone network.
Profiles of constructed networks
With these three networks in place, we conducted some network-theoretic measurements and report them in Table 1. The empirical details observed in the data (and relevant practical implications, if any) are noted below:
-
1.
The total number of accounts (after the preprocessing etc. that we described) in the dataset is 34,942; hence, considering the three networks, the majority of accounts in the phone network are singletons and are not ‘interacting’ in an obvious way with other accounts. When we consider this result in tandem with the distribution in Fig. 5 (which showed that the vast majority of accounts post only a few ads in the multi-year period in which we observed them), it suggests that the majority of the players are ‘lone’ players. A different conclusion is reached by the very broad IP Prefix AN, which is likely connecting many accounts that share no activity in the real world beyond having created the account from a common ‘Internet’ area (such as using a public computer or the Wifi network in a mall). Per the phone AN, the industry is fragmented and individualistic to a great extent. The jump in the ratio of non-singletons to total accounts in the IP AN presents a more balanced view than the extremes in the other two networks, but both its validity (as a measure of true activity) and interpretation are questionable for the reasons we mentioned earlier. A practical implication for this finding is that random interventions by either ‘social good’ actors (such as Non-Governmental Organizations or NGOs) or by investigators looking to track and prosecute human trafficking activity is unlikely to be effective, since randomly selecting an account from the data is more likely to yield a singleton or, less extremely, an account with few connections to other accounts. In contrast, a ‘network-based’ approach that seeks to investigate accounts that have high degree or connectivity in at least one of our activity networks may end up yielding insights on a broader segment of the market. Some of the other experimental findings below reinforce this notion. Furthermore, in the case studies that we describe towards the end of the article, we find that a network-based sampling of accounts is more likely to yield ‘suspicious’ signals of trafficking and involvement of young (and usually, foreign-born) individuals even compared to sampling accounts that have posted a high number of advertisements (an arguably good ‘proxy’ for measuring an account’s activity or even investigative value).
Table 1 Network measures on the three different kinds of activity networks (ANs) of which the constructions were previously described. Density, and other such metrics, were computed with respect to non-singleton nodes e.g., the density of the simple graph underlying the phone activity network is 10,882/(7041*7040/2) which is approximately 0.00044 (as reported) -
2.
The number of non-singleton nodes increases from roughly 7,000 nodes (in the phone AN) to 19,000 (in the IP AN), and number of edges increases by almost 20x. Correspondingly, density increases by more than 50% in the simple graph, though the increase is less dramatic in the multi-graph. This implies that the IP AN is introducing more connections between nodes that were previously not connected at all, as opposed to reinforcing connections that already existed. We posit that the IP AN is the equivalent of a ‘recall-friendly’ approach to modeling activity, while the phone AN is more precision-friendly. A practical implication is that, for systems attempting to use information extraction, link prediction, and other Artificial Intelligence approaches for re-constructing such relational networks from raw natural language ads and noisy attributes (Kejriwal and Szekely 2017; Chang et al. 2006; Kejriwal and Kapoor 2019), using IP ANs as a ground-truth dataset for assessing lower and upper bounds on the recall of the system is recommended, and similarly, phone ANs may be useful for assessing bounds on the precision of such a system. Beyond computational innovations, a practical use-case for sociologists and policy-makers is to use external datasets to match the IP addresses in this dataset with locations to determine whether, and to what extent, providers in online sex markets use computers and devices in public areas like libraries and cafes to post online sex advertisements. One has to be careful to account for the possibility of Virtual Private Network (VPNs) use, since the person may not be physically using the device linked to the IP address. Privacy concerns also have to be noted. We believe that other interesting hypotheses can also be formulated explaining both the similarities and differences between the phone and IP ANs. One reason to believe that the two ANs (and also the IP Prefix AN) are expressing ‘two sides of the same coin’ is the ‘directional’ similarity between the assortativity coefficients and transitivities of the networks: both seem to be expressing that the network underlying online sex markets in the UK is highly transitive, and assortative. We comment more on the implications of positive assortativity subsequently.
-
3.
The phone AN has higher transitivity (despite having lower density) than the other networks, suggesting that it may be capturing the social activity more closely than the other networks. This is also intuitive; phone numbers are known to be associated directly with sex providers (usually in a 1-1 relationship), and sharing of phone numbers across ads (and by extension, accounts) indicates either movement of the sex provider from one ring or group (represented by an account) or collaboration between groups. Hence, one practical implication of high transitivity is that the social properties of online sex market activity may be best studied by using phone ANs as proxies for a true, unknown social network. An interesting avenue for future sociological research is to conduct carefully designed field interviews and interviews with survivors of sex trafficking to refute or validate, using appropriate statistical methodologies, the hypothesis (at least in the context of advanced economies such as the UK), namely, whether a phone activity network accurately reflects the underlying real-world social network of sex workers.
-
4.
Since the phone AN is the most important of the three networks, leaving behind an activity trace that is verifiable and mirroring the features of more ordinary social networks, unlike the IP address-based ANs, we studied it closer by plotting its degree distribution in Fig. 6 on a log-log plot. We compute the power-law coefficientFootnote 9γ by regressing (using a standard linear regression package such as available in Python’s sklearn libraryFootnote 10) the log of the empirical probability of the degree (y-axis) against the degree (x-axis). The value of γ (coefficient of the x variable in the regression plot) yielded by the line of best fit was 2.17 and was significant with high R2 quality-of-fit value (Fig. 7). As we suspected earlier, the power-law coefficient (of 2.17) provides further evidence that the structure mirrors that of a social network. Since the network growth is exhibiting a power-law model, and there is positive assortativity noted for the phone AN in Table 1, preferential attachment is highly unlikely (Jeong et al. 2003). Instead, we may be observing the online sex market equivalent of the ‘rich club’ effect (Zhou et al. 2008), where high-degree nodes tend to be inter-linked, relatively speaking. There are both theoretical and practical implications to this finding. First, the question arises as to how these so-called rich clubs were formed and inter-linked to begin with. Do they represent independent organizations operating in one or more markets, or the same organization operating in different markets in the UK? The Backpage data can only give us limited answers to this, but we are nevertheless exploring them further in ongoing research by reading some of the ads. Ultimately, the answer may only be obtained through careful field interviews with sex workers. Regardless of how these organizations were formed and inter-linked, however, a practical implication (supported by some of the previous points we have raised) for investigators and NGOs alike is the importance of carefully targeting their interventions and investigations. One could potentially apply ‘network attack’ models such as presented extensively in both the disease and information diffusion literature; see, for example, Mugisha and Zhou (2016); Crucitti et al. (2004); Salathé and Jones (2010); Saito et al. (2008).
Fig. 6 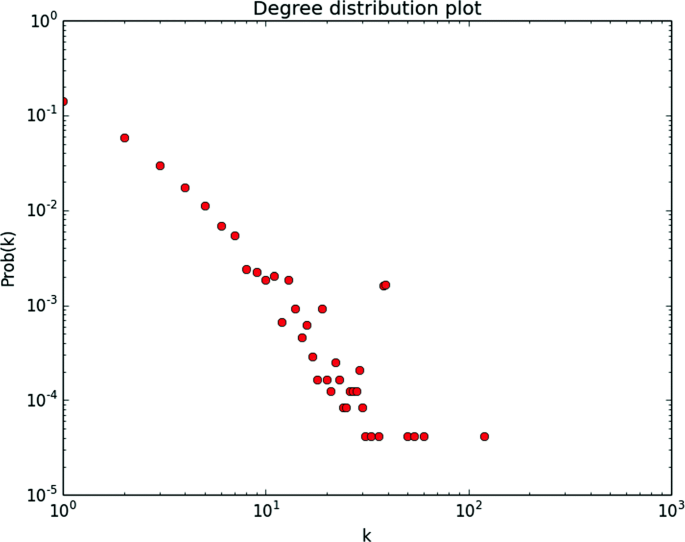
Degree distribution of phone activity network
Fig. 7 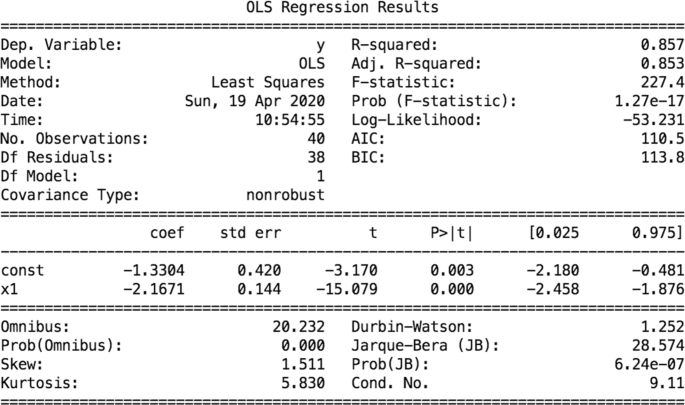
Ordinary least-squares (OLS) regression outputs for the log-transformed variables plot in Fig. 6. The negative power law coefficient for the degree distribution was found to be 2.1671 and is highly significant


To study the last point further, we also analyzed the connectivity of the phone activity network by counting the number of connected components in the network and measuring their size distributions. The total number of connected components was found to be 19,038, and the size distribution plot is shown in Fig. 8. Considering that even the non-singleton subset of the network is disconnected, with the power law distribution reinforcing the finding of fragmentation we noted earlier, the activity network starts to look different from a social network (which has higher connectivity) from this perspective.

Size distribution (number of nodes) of connected components in phone activity network
Finally, we computed the Spearman’s and Pearson’s correlation coefficients between the number of ads posted per account and the degree of the account in the phone activity network. We considered both non-singleton nodes only (i.e. non-zero degree nodes) and all nodes. For non-singleton nodes, the Spearman’s coefficient was found to be 0.2572, while Pearson’s coefficient was 0.1331. Thus, the correlation is positive, but not as high as one might expect, leading to a possible conclusion that using the number of ads in an account is a different measure of the activity of the account than the degree of the account. If we also include singletons, the measures increase: for Spearman’s coefficient, we get 0.1692, while for Pearson’s coefficient we now get 0.36278. Thus, accounts that do not post much to begin with also have lower probability of sharing activity with other accounts. These accounts most likely represent the individuals and lone players in the industry, of which there are many.
Case study
We now describe a specific case study illustrating the use of the phone activity network in identifying and profiling high-activity accounts. We consider two accounts, one with a very high number of ads (1710) posted but with relatively lower degree in the phone activity network (10), and the other with the highest degree in the phone activity network (119) but with a relatively lower (but still quite high, in an absolute sense) number of ads (911). We designate the former account as 41x648xx (we obfuscate three digits to prevent identification) and the latter account as 129x33xx.
To understand the real-world phenomena that the two accounts seem to be representing, we went beyond the statistics and sampled a set of about 50 ads from each account. We qualitatively describe our observations for each account. We note that we are not claiming that one account is of ‘higher quality’ than another on some unknown metric of collective, organizational or (potential) human trafficking activity. Rather the goal is to show how two high-activity accounts, discovered using different mechanisms, manifest in the real world.
Account 41x648xx
For account 41x648xx, we found a range of nationalities and multiple escorts advertising from the account, including girls that purported to be from Russia, Poland, Germany, Italy, Spain and even India and Colombia. For the latter two, however, it is possible that the ethnicity (rather than birthplace) is Indian and Colombian. It is also possible for more national origins or ethnicities to be revealed or discovered if we had continued sampling, but the diversity in the 50 sampled ads already illustrates that this is, by no means, a simple, individualistic or lone operation. Beyond using the same account, there did not seem to be too many similarities between these girls, and the content in the ads that we sampled clearly suggested that the account belongs to an escort service advertising sexual services. We enumerate five representative text fragmentsFootnote 11 (each from a different advertisement) below:
-
Hi Gentlemen if you’re looking for a top quality service.You found it!I’m New Surprise!Experienced Exotic.I’m Young girl From Ruusia,sensual,sexy,sweet and Friendly! <br> If you are feeling lonely,have some steamy adult fun time.
-
Hello.guys!My name is Andjela...and I’m 22 years old...I m Young sweet warm,beautiful and friendly Independent escort Girl, who is waiting to delight youFootnote 12.
-
My </a > name is Djena.I Consider my self as,Real Indian British Wooman. <br> I’m Independent High Class New in City Town London. <br> Are you a Classy Gentlemen seeking for some Conpany????You Certainly enjoy a gennuine GFE with sexy Lady Like Me.
-
I OFFER FULL SERVICES, AM independent young and energetic girl, 22 years old. The best part of escorting is I get to see interesting people and places which others dream about. from Germany sexy lady and i love red wine
-
Welcome,please allow me a moment to introduce myself.I am an Elite Gentlemen’s Companion. <br> I offer a High class service of the most exquisite quality.Whether you are planning a weekend away or looking for some private moments of pleasure.I Would love to be your <br> stunning companionFootnote 13.
We found that the service providers were all in their early 20s and there was often shared content between the ads (e.g., repetition of distinctive phrases like ‘hot party girl’ and ‘independent party girl’ was common across the ads). One reason why we believe that these girls are unique (and not just the same girl advertising in multiple different ways) is a different contact phone number listed in the main body of the ad for each individual. Another reason is the varying ethnicities, language use in ads and ages, as expressed even in the brief fragments above.
Account 129x33xx
For account 129x33xx, it is difficult to tell how many individuals are advertising from the set of 50 ads; however, with high probability there are at least two unique individuals. These individuals seemed to be Brazilian (explicitly mentioned in the text of some ads), including one female (who also advertised as transsexual in other ads), and two males (who may potentially be the same male, though they have different names in the ads, and different styles of expression). One of the males was clearing moving around the country (and stated explicitly he was on ‘tour’), with ads posted from cities as far apart as Glasgow and Birmingham. In conversations with domain experts (especially, human trafficking prosecutors and law enforcement), as well as previously published work in the computational literature, it has been suggested that high degree of movement and the presence of multiple individuals posting from the same account (and frequently changing identity), are textual ‘indicators’ of human trafficking activityFootnote 14 (Burbano and Hernandez-Alvarez 2017; Kejriwal et al. 2017; Tong et al. 2017). The other male escort changed his name frequently across ads, sometimes going by the name ‘Tyler’ and at other times, ‘Matteo’ or even ‘Bryan’Footnote 15. While there is not much we can say about the account as a whole, without looking at all ads, we can say that there is at least one female involved and one male, all with different phone numbers posted in the ad, but all posting ads from the same account. Almost all members of the group are Brazilian (and new to the UK from the ad texts).
It is clear that the individual who was moving around rented apartments every now and then (‘now in a luxury flat in old street station’; ‘now in a luxury flat in Lancaster Gate’). There is at least one other ad where a female escort claims she is from Colombia and is ‘back to UK’. This may be false, or it may suggest a broader ring. We note that the style of her ad is similar to that of the transsexual escort from Brazil. Without looking at the images (not available for this study), we cannot determine whether these individuals are unique or not. This lends credence to a point we made earlier about the utility of designating accounts, rather than individuals, as the primary unit of study when processing and profiling online sex advertisements at scale.
Many of the individuals in these ads claim that they are ‘independent’ in the ad text, but this may simply be a signal to the customer that they operate alone. The open question revealed by this case study, which can only be determined through offline methods, is how these individuals met and started using the same account to begin with, and whether they are being trafficked or coming into the country through illegitimate means, considering there is evidence of travel both within and without the country per the ad text. There are also a wide range of services on offer for a motley collection of escorts; across the ads, we observed services ranging from dinner dates to bondage and tantric massages being offered. Some of the ads had social media accounts as well, including Snapchat and Instagram, suggesting that the advertising is not limited just to Backpage ads. More disturbingly, the ads suggest that very young escorts are involved e.g., Matteo lists his age as 19 but offers many services. On Backpage, it is well known that providers sometimes overstate their age so that they are not flagged by the systemFootnote 16.
Comparing the two accounts, it is evident that account 129x33xx has lower density of individuals per ad compared to account 41x648xx (i.e. the former account is advertising fewer unique individuals, or individuals that are otherwise hard to disambiguate). Furthermore, it is more homogeneous in terms of ethnicity (every ad is advertising someone of South American descent, mostly Brazilian), but heterogeneous in terms of services offered. Some of the trafficking indicators, such as movement, are present in that account as well. In contrast, the account 41x648xx seems to have higher number of individuals who fit a homogeneous profile in terms of age, gender, category placement of ads and types of services offered (and also the text/content in the ads themselves). The account has all the features of an escort agency catering to a specific customer base, with the primary source of diversity arising in the exotic origins of the girls (mostly from Europe, but with some ads also showcasing Indian girls).
Future work
Network science is a useful paradigm for studying the structural properties of interesting and complex systems, including online sex markets. The set of results produced in this paper illustrated some insightful phenomena, but they also raised some questions that are best left for future research. Below, we specify some promising avenues for such research:
-
1.
While we did not distinguish in this article between the different categories such as ‘escorts’, ‘male escorts’ etc.; see Figure 4), there is enough data available for a selective analysis conditioned on some categories. By studying categories separately, interesting behavior may emerge, since each category represents a potential ‘sub-market’ in the domain. It is also possible that, on some structural measures, we encounter novel statistical phenomena such as Simpson’s paradox (Wagner 1982), wherein the network behavior of a particular category behaves very differently compared to the ‘overall’ (i.e. including all categories) network of ads and accounts that we have studied. Finding evidence of Simpson’s paradox among certain categories may yield interesting insights into the behavior of providers in the market.
-
2.
A worthwhile agenda is studying the network from the perspective of account centrality (Bonacich 1987; Das et al. 2018). In the case study, for example, we considered two definitions of account importance, one of which relied on the number of ads posted per account, and the other of which relied on the degree of the account in the phone activity network. From a centrality perspective, the latter is an instance of using the degree centrality to measure the importance of a node in the overall system. However, many other measures of centrality exist, including betweenness, current flow and closeness centralities (Bavelas 1948; Newman 2005). For several decades now, researchers have found strong evidence that these different measures of centrality, far from being equivalent, seem to express radically different social phenomena in the underlying system (Freeman 1978). It is an open question as to what phenomena these centralities will map to in the context of our particular domain (online sex networks) and country (UK). One way to uncover the varying sociological interpretations of different centrality measures is by combining a quantitative analysis with qualitative, sampling-based case studies on accounts exhibiting high and low values on these measures.
-
3.
While the network is disconnected (even when considering non-singletons alone), the distribution of connected component sizes reveals a power law distribution, with clear presence of both large-sized clusters and ‘isolates’ (small, fragmented clusters). Some of the larger clusters may be worthwhile studying further, since they may indicate highly illicit activities of an organized nature, such as trafficking.
-
4.
To ensure accuracy, we only used reliable attributes such as phone numbers and IP addresses available in the metadata in the Backpage corpus that law enforcement provided us with. However, given the improved performance of Artificial Intelligence and Natural Language Processing algorithms, we may want to consider applying methods such as information extraction (Kejriwal and Szekely 2017; Chang et al. 2006) to obtain a broader set of values (such as prices) from the ad text that are not currently available from the metadata. Even with some noise, the resulting attributed network may yield valuable insights using (for example) attribute assortativity analysis.
Conclusion
Online sex marketplaces are complex domains that have been difficult to study thus far at the scale of hundreds of thousands of advertisements posted on a common portal, for a common region. Data availability has been an important barrier historically, but even with the advent of Web crawlers, bias in the crawl, and lack of crucial information such as correctly extracted phones and account identifiers, have all served as impediments to robust analysis of such marketplaces using the tools of applied network science. In this article, we preprocessed, profiled and constructed activity networks from UK Backpage data, especially backend data that allowed us to infer properties otherwise not possible to infer using only the ad text. Our findings reveal that, by and large, the industry is highly fragmented and individualistic in the UK, but that the active subset of the network (involving non-singletons) is non-trivial in an absolute sense, involving thousands of accounts even when using the precision-friendly shared-phone methodology for constructing the networks. There are other interesting findings that may merit further comparison to other network studies. For example, we show that, when using shared phones as an activity signal, the resulting network resembles a social network and can be studied further. We did brief, qualitative case studies on two highly active accounts, one of which was chosen because it ranked high on activity in our network (rather than the raw metric of the posted number of ads). We found that the accounts, despite both being high-activity, manifest unique kinds of activity in the real world. We plan to expand the scope of our case studies, and conduct other such studies in future work.
Availability of data and materials
The authors confirm that the data on which experiments were conducted has been acquired ethically and with permission from the federal law enforcement in the United States who are investigating Backpage. The UK subset of the data (and the results demonstrated in this paper) is not being used for any investigation and no analysis in this paper is linked to (to our knowledge), was influenced by, or has bearing on, any past or current investigation in the UK.
Neither the raw data nor phone information can be released due to the sensitivity of the material. We can address data-related questions or concerns that the reviewers might have on a case-by-case basis, and we may be able to release derived data (e.g., statistical data of two vectors demonstrating correlations between number of ads/account and degrees etc.)
Notes
See notice on backpage.com
Or otherwise looked at the demand side of online sex, rather than the supply side, usually by placing decoy ads and measuring response; see, for example, the work by Roe-Sepowitz et al. (2016).
There is a many-one relationship between accounts and ads, on the other hand, since an ad, itself identified by a unique identifier, must have been posted from (exactly) one account.
Multiple articles describing human trafficking have used the term ‘ring’ to describe such groups; e.g., see Smith and Smith (2011) and Jones (2010).
That is, under the power-law assumption that P(d)∝d−γ, where d is the degree and P(d) is the empirical probability of observing that degree.
We show the fragments without any kind of preprocessing (we also retain the HTML tags embedded in the source text), but we remove newlines where present in the original HTML formatting.
In the title, but not the main body, of this advertisement, the provider mentioned that she was a ‘Colombian lady’.
In both the title and main body of the ad, the provider states that she is from Poland.
As further evidence, computational tools for mining these indicators from ad text were also used developed during the DARPA MEMEX program (Fox-Brewster 2015), which funded computational work on detecting and classifying human trafficking activity online, and actively conferred with, and transitioned technology to, human trafficking prosecution units both during, and in the aftermath of, the course of the program.
This is also true for the female or transsexual escort.
We have never found any sex providers listing a non-zero age below 18 in either the UK or US data so far, which may mean that it was simply not permitted by the system to begin with. However, a non-trivial fraction of providers that had age 18 or 19 have been found to be underage.
Abbreviations
- UK:
-
United Kingdom
- AN:
-
Activity network
- IP:
-
Internet protocol
- FBI:
-
Federal bureau of investigation
- US:
-
United States
- CEO:
-
Chief executive officer
- Ad:
-
Advertisement
- NGO:
-
Non-governmental organization
- DIG:
-
Domain-specific insight graphs
- HTML:
-
HyperText Markup Language
- ID:
-
Identifier
References
Adriaenssens, S, Hendrickx J (2012) Sex, price and preferences: Accounting for unsafe sexual practices in prostitution markets. Sociol Health Illn 34(5):665–680.
Alvari, H, Shakarian P, Snyder JK (2016) A non-parametric learning approach to identify online human trafficking In: 2016 IEEE Conference on Intelligence and Security Informatics (ISI).. IEEE. https://doi.org/10.1109/isi.2016.7745456.
Alvari, H, Shakarian P, Snyder JK (2017) Semi-supervised learning for detecting human trafficking. Secur Inform 6(1):1.
Baglay, S (2020) Access to compensation for trafficked persons in canada. J Hum Trafficking:1–30. https://doi.org/10.1080/23322705.2020.1738144.
Barabási, A-L, et al. (2016) Network science.
Bavelas, A (1948) A mathematical model for group structures. Appl Anthropol 7(3):16–30.
Berger, SI, Iyengar R (2009) Network analyses in systems pharmacology. Bioinformatics 25(19):2466–2472.
Bradbury, D (2014) Unveiling the dark web. Netw Secur 2014(4):14–17.
Bonacich, P (1987) Power and centrality: A family of measures. Am J Sociol 92(5):1170–1182.
Borgatti, SP, Mehra A, Brass DJ, Labianca G (2009) Network analysis in the social sciences. science 323(5916):892–895.
Burbano, D, Hernandez-Alvarez M (2017) Identifying human trafficking patterns online In: 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM).. IEEE. https://doi.org/10.1109/etcm.2017.8247461.
Capiola, A, Griffith JD, Balotti B, Turner R, Sharrah M (2014) Online escorts: The influence of advertised sexual orientation. J Bisexuality 14(2):222–235.
Chang, C-H, Kayed M, Girgis MR, Shaalan KF (2006) A survey of web information extraction systems. IEEE Trans Knowl Data Eng 18(10):1411–1428.
Chantavanich, S (2020) Thailand’s challenges in implementing anti-trafficking legislation: The case of the rohingya. J Hum Trafficking:1–10. https://doi.org/10.1080/23322705.2020.1691825.
Chen, P, Redner S (2010) Community structure of the physical review citation network. J Informetrics 4(3):278–290.
Chen, H. (2011) Dark web: Exploring and data mining the dark side of the web.
Crucitti, P, Latora V, Marchiori M, Rapisarda A (2004) Error and attack tolerance of complex networks. Physica A: Statistical mechanics and its applications 340(1-3):388–394.
Das, K, Samanta S, Pal M (2018) Study on centrality measures in social networks: a survey. Soc Netw Anal Min 8(1):13.
Della Giusta, M, Di Tommaso ML, Strøm S (2009) Who is watching? the market for prostitution services. J Popul Econ 22(2):501–516.
Doan, A., Halevy A., Ives Z. (2012) Principles of data integration. Elsevier. https://doi.org/10.1016/C2011-0-06130-6.
Easley, D, Kleinberg J, et al. (2010) Networks, Crowds, and Markets vol. 8. Cambridge University Press, Cambridge.
Edelman, B, Stemler A (2019) From the digital to the physical: Federal limitations on regulating online marketplaces. Harv J on Legis 56:141.
Farrell, A, de Vries I (2020) Measuring the nature and prevalence of human trafficking. In: Winterdyk J Jones J (eds)The Palgrave International Handbook of Human Trafficking, 147–162.. Palgrave Macmillan, Cham.
Fox-Brewster, T. (2015) Memex in action: Watch darpa artificial intelligence search for crime on the ‘dark web,’. Forbes 10. https://www.forbes.com/sites/thomasbrewster/2015/04/10/darpa-memex-search-going-open-source-check-it-out/#207ecb142812.
Finklea, KM (2015) Dark web.
Freeman, LC (1978) Centrality in social networks conceptual clarification. Soc Netw 1(3):215–239.
Gavin, A-C, Bösche M, Krause R, Grandi P, Marzioch M, Bauer A, Schultz J, Rick JM, Michon A-M, Cruciat C-M, et al. (2002) Functional organization of the yeast proteome by systematic analysis of protein complexes. Nature 415(6868):141.
George, A, Vindhya U, Ray S (2010) Sex trafficking and sex work: Definitions, debates and dynamics?a review of literature. Econ Polit Wkly 45(17):64–73.
Greenberg, SA (2009) How citation distortions create unfounded authority: analysis of a citation network. Bmj 339:2680.
Greiman, V., Bain C. (2013) The emergence of cyber activity as a gateway to human trafficking. In: Hart D (ed)Proceedings of the 8th International Conference on Information Warfare and Security: ICIW 2013, 90–96.. Academic Conferences Limited, Denver.
Haasz, A (2015) Underneath it all: Policing international child pornography on the dark web. Syracuse J Int L Com 43:353.
Harrendorf, S, Heiskanen M, Malby S (2010) International statistics on crime and justice In: European Institute for Crime Prevention and Control, affiliated with the United Nations (HEUNI.. UNODC and Helsinki, Finland: HEUNI, Geneva.
Hogan, A, Harth A, Umrich J, Decker S (2007) Towards a scalable search and query engine for the web In: Proceedings of the 16th international conference on World Wide Web - WWW ’07.. ACM. https://doi.org/10.1145/1242572.1242819.
Hultgren, M, Jennex ME, Persano J, Ornatowski C (2016) Using knowledge management to assist in identifying human sex trafficking In: 2016 49th Hawaii International Conference on System Sciences (HICSS).. IEEE. https://doi.org/10.1109/hicss.2016.539.
Hummon, NP, Dereian P (1989) Connectivity in a citation network: The development of dna theory. Soc Netw 11(1):39–63.
Hurlburt, G (2017) Shining light on the dark web. Computer 50(4):100–105. https://doi.org/10.1109/mc.2017.110.
Jeong, H, Néda Z, Barabási A-L (2003) Measuring preferential attachment in evolving networks. EPL Europhysics Lett 61(4):567.
Jones, SV (2010) The Invisible Man: The Conscious Neglect of Men and Boys in the War on Human Trafficking, 2010 Utah L. Rev. 1143. https://repository.jmls.edu/cgi/viewcontent.cgi?article=1029&context=facpubs.
Jones, A (2015) Sex work in a digital era. Sociol Compass 9(7):558–570.
Kapoor, R, Kejriwal M, Szekely P (2017) Using contexts and constraints for improved geotagging of human trafficking webpages. arXiv preprint arXiv:1704.05569.
Kejriwal, M, Szekely P (2017) Information extraction in illicit web domains In: Proceedings of the 26th International Conference on World Wide Web.. International World Wide Web Conferences Steering Committee. https://doi.org/10.1145/3038912.3052642.
Kejriwal, M., Ding J., Shao R., Kumar A., Szekely P. (2017) Flagit: A system for minimally supervised human trafficking indicator mining. arXiv preprint arXiv:1712.03086.
Kejriwal, M, Kapoor R (2019) Network-theoretic information extraction quality assessment in the human trafficking domain. Appl Netw Sci 4(1):44.
Kleinberg, JM (2007) Challenges in mining social network data: processes, privacy, and paradoxes In: Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 4–5.. ACM. https://doi.org/10.1145/1281192.1281195.
Knoke, D., Yang S. (2008) Social Network Analysis, vol. 154. Sage, Thousand Oaks.
Kruithof, K, Aldridge J, Hétu DD, Sim M, Dujso E, Hoorens S (2016) The role of the’dark web’in the trade of illicit drugs. https://doi.org/10.7249/rb9925.
Lee, S, Yoon C, Kang H, Kim Y, Kim Y, Han D, Son S, Shin S (2019) Cybercriminal minds: An investigative study of cryptocurrency abuses in the dark web In: NDSS. https://doi.org/10.14722/NDSS.2019.23055.
Leskovec, J, Huttenlocher D, Kleinberg J (2010) Predicting positive and negative links in online social networks In: Proceedings of the 19th International Conference on World Wide Web, 641–650.. ACM. https://doi.org/10.1145/1772690.1772756.
Li, X, Chen H, Huang Z, Roco MC (2007) Patent citation network in nanotechnology (1976–2004). J Nanoparticle Res 9(3):337–352.
Lin, T, Pantel P, Gamon M, Kannan A, Fuxman A (2012) Active objects: Actions for entity-centric search In: Proceedings of the 21st international conference on World Wide Web - WWW ’12.. ACM. https://doi.org/10.1145/2187836.2187916.
Logan, TD, Shah M (2013) Face value: information and signaling in an illegal market. South Econ J 79(3):529–564.
Martin, J (2014) Drugs on the Dark Net: How Cryptomarkets Are Transforming the Global Trade in Illicit Drugs. Springer. https://doi.org/10.1057/9781137399052.
Moreno, JL (1946) Sociogram and sociomatrix. Sociometry 9:348–349.
Mugisha, S, Zhou H-J (2016) Identifying optimal targets of network attack by belief propagation. Phys Rev E 94(1):012305.
Newman, ME (2005) A measure of betweenness centrality based on random walks. Soc Netw 27(1):39–54.
O’Connor, M, Healy G (2006) The links between prostitution and sex trafficking: A briefing handbook. EWL/CATW.
Portnoff, RS, Huang DY, Doerfler P, Afroz S, McCoy D (2017) Backpage and bitcoin: Uncovering human traffickers In: Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1595–1604.. ACM. https://doi.org/10.1145/3097983.3098082.
Rabbany, R, Bayani D, Dubrawski A (2018) Active search of connections for case building and combating human trafficking In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.. ACM. https://doi.org/10.1145/3219819.3220103.
Rhodes, LM (2016) Human trafficking as cybercrime. Agora Int J Admn Sci 1(1):23–29.
Rhumorbarbe, D, Werner D, Gilliéron Q, Staehli L, Broséus J, Rossy Q (2018) Characterising the online weapons trafficking on cryptomarkets. Forensic Sci Int 283:16–20.
Roe-Sepowitz, D, Bontrager Ryon S, Hickle K, Gallagher JM, Hedberg E (2016) Invisible offenders: estimating online sex customers. J Hum Trafficking 2(4):272–280.
Saito, K, Nakano R, Kimura M (2008) Prediction of information diffusion probabilities for independent cascade model In: International Conference on Knowledge-based and Intelligent Information and Engineering Systems, 67–75.. Springer. https://doi.org/10.1007/978-3-540-85567-5_9.
Salathé, M, Jones JH (2010) Dynamics and control of diseases in networks with community structure. PLoS Comput Biol 6(4).
Saleiro, P, Teixeira J, Soares C, Oliveira E (2016) Timemachine: Entity-centric search and visualization of news archives In: Lecture Notes in Computer Science, 845–848.. Springer. https://doi.org/10.1007/978-3-319-30671-1_78.
Sanders, T. (2013) Sex Work. Routledge, Abingdon.
Savona, EU, Stefanizzi S (2007) Measuring human trafficking. Springer. https://doi.org/10.1007/0-387-68044-6.
Schreiber, F, Schwöbbermeyer H (2005) Mavisto: a tool for the exploration of network motifs. Bioinformatics 21(17):3572–3574.
Shuai, H, Liu J (2020) Human trafficking in china. In: Winterdyk J Jones J (eds)The Palgrave International Handbook of Human Trafficking, 1241–1253.. Palgrave Macmillan, Cham. https://link.springer.com/referenceworkentry/10.1007%2F978-3-319-63192-9_130-1#citeas .
Smith, CA, Smith HM (2011) Human trafficking: The unintended effects of united nations intervention. Int Polit Sci Rev 32(2):125–145.
Szekely, P, Knoblock CA, Slepicka J, Philpot A, Singh A, Yin C, Kapoor D, Natarajan P, Marcu D, Knight K, et al. (2015) Building and using a knowledge graph to combat human trafficking In: International Semantic Web Conference, 205–221.. Springer. https://doi.org/10.1007/978-3-319-25010-6_12.
Tong, E, Zadeh A, Jones C, Morency L-P (2017) Combating human trafficking with multimodal deep models In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).. Association for Computational Linguistics. https://doi.org/10.18653/v1/p17-1142.
Tonon, A, Demartini G, Cudré-Mauroux P (2012) Combining inverted indices and structured search for ad-hoc object retrieval In: Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval - SIGIR ’12.. ACM. https://doi.org/10.1145/2348283.2348304.
Tyler, A (2014) Advertising male sexual services:82–105.
Wagner, CH (1982) Simpson’s paradox in real life. Am Stat 36(1):46–48.
Wasserman, S, Faust K (1994) Social Network Analysis: Methods and Applications, vol. 8. Cambridge university press, Cambridge.
Weimann, G (2016) Going dark: Terrorism on the dark web. Stud Confl Terrorism 39(3):195–206.
Wernicke, S, Rasche F (2006) Fanmod: a tool for fast network motif detection. Bioinformatics 22(9):1152–1153.
Williams, K (2013) Untangling the dark web: Taking on the human sex trafficking industry. IEEE Women Eng Mag 7(2):23–26.
Zhou, J, Xu X, Zhang J, Sun J, Small M, Lu J-A (2008) Generating an assortative network with a given degree distribution. Int J Bifurcation Chaos 18(11):3495–3502.
Zulkarnine, AT, Frank R, Monk B, Mitchell J, Davies G (2016) Surfacing collaborated networks in dark web to find illicit and criminal content In: 2016 IEEE Conference on Intelligence and Security Informatics (ISI), 109–114.. IEEE. https://doi.org/10.1109/ISI.2016.7745452.
Acknowledgements
Not Applicable.
Funding
This research was funded by an endowment by the Keston family.
Author information
Authors and Affiliations
Contributions
Authors’ contributions
Kejriwal has primarily contributed to the ideas, experimental design and reporting in this work, while Gu’s contributions have been analytical and running the experiments. Kejriwal contributed to all of the writing. Both authors read and approved the final manuscript.
Authors’ information
Dr. Mayank Kejriwal (PhD, Computer Science) is a research assistant professor (Industrial and Systems Engineering), and a research lead (Information Sciences Institute) at the University of Southern California in Los Angeles, California. Dr. Kejriwal research has primarily been funded by DARPA, and involves research in AI and social network analysis for social impact problems such as human trafficking and crisis informatics. Dr. Kejriwal is a member of the Center on Knowledge Graphs at ISI, and has published papers across several AI areas. He is the author of ‘Domain-specific Knowledge Graph Construction’ (Springer, 2019) and an author of an upcoming textbook on knowledge graphs as well. He has successfully transitioned work products to law enforcement for fighting human trafficking by locating suspicious activity in corpora of sex ads.
Yao Gu completed his Masters in Computer Science at the University of Southern California in May 2019. While pursuing his studies, he worked as a student researcher at the Information Science Institute under Dr. Kejriwal’s supervision, with a focus on network analytics and applications of machine learning to problems such as detecting human trafficking activity and crisis informatics.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kejriwal, M., Gu, Y. Network-theoretic modeling of complex activity using UK online sex advertisements. Appl Netw Sci 5, 30 (2020). https://doi.org/10.1007/s41109-020-00275-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41109-020-00275-1