- Research
- Open access
- Published:
When can overambitious seeding cost you?
Applied Network Science volume 4, Article number: 38 (2019)
Abstract
In the classic “influence-maximization” (IM) problem, people influence one another to adopt a product and the goal is to identify people to “seed” with the product so as to maximize long-term adoption. Many influence-maximization models suggest that, if the number of people who can be seeded is unconstrained, then it is optimal to seed everyone at the start of the IM process. In a recent paper, we argued that this is not necessarily the case for social products that people use to communicate with their friends (Iyer and Adamic, The costs of overambitious seeding of social products. In: International Workshop on Complex Networks and Their Applications_273–286, 2018). Through simulations of a model in which people repeatedly use such a product and update their rate of subsequent usage depending upon their satisfaction, we showed that overambitious seeding can result in people adopting in suboptimal contexts, having bad experiences, and abandoning the product before more favorable contexts for adoption arise. Here, we extend that earlier work by showing that the costs of overambitious seeding also appear in more traditional threshold models of collective behavior, once the possibility of permanent abandonment of the product is introduced. We further demonstrate that these costs can be mitigated by using conservative seeding approaches besides those that we explored in the earlier paper. Synthesizing these results with other recent work in this area, we identify general principles for when overambitious seeding can be of concern in the deployment of social products.
Introduction
The study of how new ideas and products spread through networks dates back decades, to early studies from the 1950s and 1960s of the adoption of health innovations (Coleman et al. 1957; 1959; 1966) and to the development of general models of product adoption by Rogers and Bass (Rogers 1962; Bass 1969). An important milestone was the formulation of “influence maximization” (IM) as an algorithmic problem by Domingos and Richardson (2001). In IM, a product developer typically has limited resources (e.g., an advertising budget) with which to give or market a product to potential adopters. The developer assumes that adoption of the product spreads through the social network of potential adopters through some peer-influence process. Then, the challenge is to decide which people to “seed” with the product in order to maximize long-term adoption. Since its formulation by Domingos and Richardson, the influence maximization problem has found applications across diverse domains, from traditional applications in marketing (Hinz et al. 2011), to the spreading of health information (Yadav et al. 2018; Wilder et al. 2018), to the diffusion of microfinance programs in villages (Banerjee et al. 2013).
Influence maximization has been theoretically studied under a variety of peer-influence models. One classic IM model is the independent-cascade model, in which friends of new adopters also adopt with some probability (Goldenberg et al. 2001). So-called linear threshold models comprise another class, in which people will adopt if sufficiently many of their friends adopt (Granovetter 1978; Schelling 2006). Depending upon the specific threshold model, an individual’s adoption decision can depend upon a minimum number of friends adopting or upon a minimum percentage of friends adopting (Watts 2002). Soon after the formulation of IM by Domingos and Richardson, Kempe, Kleinberg, and Tardos demonstrated both that IM is NP-hard under the usual independent cascade and threshold models and that there are nevertheless simple greedy algorithms for selecting the seeds with strong performance guarantees (Kempe et al. 2003). Their work has inspired a large literature around developing even better heuristic algorithms for IM. A recent review of state-of-the-art algorithms can be found in Li et al. (2018).
In this paper, we revisit a question that we previously explored in Iyer and Adamic (2018): if there is no budgetary constraint on seeding, is it optimal to seed everyone at the start of the IM process? Despite the general hardness of IM, the traditional independent cascade and threshold models all agree that the answer to this question is “yes.” Does that property of these simplified models provide reasonable guidance for real product-deployment scenarios? There are several reasons why it may not, including costs associated with people rejecting the product, downstream word-of-mouth effects, and so-called “non-conformism” effects, where people are inclined to adopt less popular products. We review prior work on each of these pathways to “overexposure” in the “Related work” section below.
Our main focus here, however, is on a distinct pathway to overexposure, which we demonstrated in a recent paper (Iyer and Adamic 2018): when the product under consideration is one that allows people to communicate with their friends (i.e., a “social” product), if people adopt too early, then they may begin using the product in contexts where insufficiently many of their friends are using it. This can lead to abandonment of the product prior to the emergence of a more favorable context for adoption. In our earlier paper, we showed that a more conservative seeding strategy can often help avoid these premature abandonments of the product and lead to greater long-term usage. Crucially, we showed that this remains true even in the absence of a budgetary constraint on initial seeding: even if a product developer can simply hand the product to everybody, it may be preferable not to do so.
The present paper extends our previous work in various ways. In Iyer and Adamic (2018), we demonstrated the “costs” of overambitious seeding in a model of repeated product usage, where people gain access to a social product and then either use the product or abstain in a sequence of time steps. Here, we show that these “costs” also appear in more traditional threshold models, once the possibility of permanent abandonment of the product (also referred to as “churn”) is introduced. Furthermore, through simulations on networks with a clear community structure, our earlier work showed that seeding approaches that focus on one of the clusters can often outperform approaches that seed the entire network. In this paper, we show that there are conservative seeding approaches that do not rely on clear-cut community structure, but which still lead to greater longer-term adoption than universal seeding. After demonstrating the robustness of our previous results in these two different ways, we then attempt to abstract away general principles for when product developers ought to factor these considerations into their product deployment decisions.
The rest of this paper is structured as follows. The “Related work” section places our work in the context of prior research on overexposure in IM. With this context in place, in the “Models of social-product usage” section, we introduce the repeated-usage and threshold models that we study in this paper. Next, in the “Toy examples” section, we study each of these models on certain, very special network structures, developing intuitions for why overambitious seeding can be problematic in both models. In practice, of course, we will want to see how the models behave on more realistic network structures, and to that end, in the “Networks used in simulations” section we introduce the real-world network structures that we use in our numerical simulations. The “Simulation results: cluster-based seeding” and the “Simulation results: k-core seeding” sections then report our simulation results, showing how two different conservative seeding approaches can outperform universal seeding. In the “Discussion: When is overambitious seeding costly?” section, we extract some general principles for when overambitious seeding can be costly before concluding in the “Conclusion” section by reviewing our findings and pointing out opportunities for extensions.
Related work
In this section, we review research on overexposure and overambitious seeding in influence maximization. Our goal here will be to examine the implications of various previously explored models for the fundamental question articulated above: in the absence of a budgetary constraint on the seeding process, is it optimal to seed everyone immediately? This survey of prior research helps distill the reasons why it is interesting that, in each of the models studied in this paper, the answer to this question is often “no.”
In Kempe et al. (2003), the authors showed that the classic independent cascade and linear threshold models obey a monotonicity property, where a subset of a cohort of initial adopters cannot lead to higher long-term adoption than the entire cohort. Furthermore, they generalized these models to a larger class of so-called “triggering” models, in which each subset of a person i’s neighbors is associated with a probability of i adopting, and showed that triggering models also exhibit monotonicity (Kempe et al. 2003). If this monotonicity property holds, and if each person accepts the seed independently, then the optimal approach in the unbudgeted case clearly involves seeding everybody: an unseeded individual’s probability of adoption in the seed round is 0, and by monotonicity, it would be preferable if that probability was non-zero.
Models of overexposure generally try to show that there are plausible assumptions about real-world IM settings that can violate monotonicity. One path to overexposure involves introducing some type of negative payout for rejection of the product. A recent example of this can be found in Abebe et al. (2018), in which the authors study a diffusion process where there are positive payouts for adopters and negative payouts for rejecters. If someone adopts, that person will refer the product to his or her friends, which could result in further adoptions or rejections. In this model, there can be circumstances where it is detrimental to seed an individual i, because the costs of the product being exposed to i’s friends may outweigh the benefits of i’s adoption. In the unbudgeted case, the optimal strategy still does not generally involve seeding everyone, because that would expose the product to many rejecters, leading to potentially avoidable negative payouts (Abebe et al. 2018). The results of Abebe et al. echo empirical findings such as the so-called Groupon effect, where exposure to a larger audience can have unintended negative effects (e.g., upon Yelp ratings) (Byers et al. 2012).
Other authors have studied overexposure effects arising from more direct negative externalities of adoption, such as “negative word-of-mouth” (Kiesling et al. 2012). Empirical research actually suggests that dissatisfied adopters spread their perspective more often than satisfied adopters, sharing their negative sentiment with up to ten friends (Anderson 1998). Cui et al. recently reported results for a model where satisfied adopters can enhance the probability of subsequent adoption by their friends, while dissatisfied adopters can reduce that probability (Cui et al. 2018). In such a setting, it may be preferable to seed people who are likely to spread positive word-of-mouth and avoid seeding others.
“Non-conformist” or “hipster” effects comprise yet another class of negative externalities. “Hipsters” in these models refrain from adopting products that are too popular and/or abandon products if they become too popular (Alkemade and Castaldi 2005). Although not strictly framed as an IM study, the recent work of Juul and Porter shows how the presence of hipsters can have dramatic effects upon the long-term adoption of two competing products. Indeed, in some cases, the product that begins the process with no adopters at all ends up accounting for the majority in the steady state (Juul and Porter 2019).
Kempe, Kleinberg, and Tardos referred to models in which adopters can revert to the non-adopting state as “non-progressive” models, to contrast with “progressive” models where people can only transition into the adopting state. If we want to consider the product experiences of people after they make their initial adoption decision, then some form of non-progressive model is appealing. Kempe et al. showed that the simplest non-progressive extensions of monotonic triggering models (e.g., where people abandon the product if enough of their friends do) inherit the monotonicity property. This is because these models can be mapped to their progressive counterparts on a temporal network in which people are represented by a node in each temporal layer, and there are links between each person i at time t and their friends at time t−1Footnote 1 (Kempe et al. 2003). This argument for monotonicity does not work if the original progressive model is itself non-monotonic, or if people abandon the product permanently after a fixed number of adoptions.
In Iyer and Adamic (2018), we previously argued that it can be detrimental to seed everyone at the start of an unbudgeted IM process in a certain type of non-progressive model, even in the absence of the mechanisms studied in the previous literature surveyed above. Our model was motivated by “social products” that are used by friends to communicate with one another, and it considered the product experiences of people after adoption instead of focusing exclusively upon the binary adoption / rejection process. A key point of our earlier paper was that taking into account these product experiences naturally leads to the emergence of costs of overambitious seeding, even in the absence of negative payouts of rejection, negative word-of-mouth, and non-conformism effects. However, we made this point in a model that is rather structurally different from classic models of IM (Iyer and Adamic 2018). Here, we show that the same mechanisms can lead to costs of overambitious seeding in traditional threshold models, once the possibility of permanent churn is included.
Models of social-product usage
In this section, we introduce two models of how people adopt, use, and abandon social products. First, we review the model of repeated product usage that was proposed in reference (Iyer and Adamic 2018), which considers the gradual impact of individual product experiences upon people’s subsequent behavior. Then, we propose a modification of the traditional threshold model as a “coarser-grained” model of long-term adoption decisions.
Both models are intended to describe the choices of people embedded in an undirected social network. Each node i represents a person who can potentially use or adopt the product. Each edge ij represents a friendship tie between two people.
Repeated-Usage Model: Our repeated-usage model proceeds in a sequence of time steps, beginning with t=0. At any time t, a person i can either have access to the product or not. People can only use the product in time step t if the have received access by that time. If a person i has access, then i uses the product in that time step with probability pi(t) and abstains otherwise. At the time ti when i initially gets access, pi(ti) is initialized to a value p0.
We associate a threshold si with each person. If i uses the product in time step t, then si is the number of friends of i who also need to use the product at time t for i to be satisfied. Then, i adjusts his or her probability of subsequent usage up or down as follows:
We allow pi(t) to grow to 1 or drop to 0. While pi(t)=1 is not necessarily a permanent state, pi(t)=0 is permanent, because it guarantees that the person will no longer have any product experiences, and consequently, will have no opportunities to increment their usage.
In this model, in situations where we do not give access to everyone at time t=0, we need some protocol for implementing the gradual expansion of access. As in Iyer and Adamic (2018), we expand access to a new person when they have had at least two friends using the product in each of five consecutive time steps. This is one example of a more conservative seeding strategy than universal seeding at t=0. Other variants of this rule can certainly be considered and may even lead to better long-term outcomes, but this choice suffices to demonstrate our main results.
Threshold Model with Churn: Various types of threshold models have been proposed in a number of contexts, from models of percolation in statistical physics (Adler 1991) to collective models of social behavior (Granovetter 1978; Watts 2002). When these models are used to study the decisions of people situated in a social network, the general idea is that people are able to take on one of two states, which we can refer to as “adopting” and “non-adopting.” Certain people begin in the adopting state (e.g., through the outcome of a seeding process). Then, others may adopt if sufficiently many of their friends are in the adopting state. The adoption rule may be formulated in terms of the absolute number of friends, or alternatively, it may be formulated in terms of a percentage of friends. Generally, the adoption rule is iteratively applied until no more people would adopt.
In “non-progressive” threshold models, people can also transition out of the adopting state. For example, as an outcome of the seeding process, some people can find themselves in a situation where insufficiently many of their friends are adopting. In these circumstances, they may transition back to the non-adopting state. This can, in turn, leave others in a situation where they have too few adopting friends, leading to more defections. These transitions out of the non-adopting state will, in general, cooccur and compete with transitions into the adopting state over time. If people are willing to adopt the product an arbitrary number of times, then the non-progressive model can be mapped to a progressive model and is monotonic in the size of the original seed set (Kempe et al. 2003). However, if people permanently churn after a fixed number of adoptions, then the non-progressive model is not necessarily monotonic.
The threshold model that we study here proceeds as follows:
-
Seeding Stage: At time t=0, certain people within a social network are offered the product, which they adopt with acceptance probability pa.
-
State Updates: At each subsequent time step t=1,2,3,…, people update their states in two successive waves, which continue until the process converges:
-
1
Adoption Round: People who are not currently adopting look at the states of their friends after the previous churn round (at time step t−1)Footnote 2 and adopt if at least si of their friends are adopting.
-
2
Churn Round: People who are currently adopting look at the states of their friends after the previous adoption round (at time step t) and churn if fewer than si of their friends are adopting.
-
1
-
Constraints on State Changes: The state updates described above are constrained by the following two rules:
-
1
One-Time-Step Commitment: People who adopt in time step t’s adoption round do not immediately churn in time step t’s churn round. There is a rate limit to these state changes because we are modeling long-term changes in people’s attitudes towards the product.
-
2
Single Adoption per Person: People give the product only one chance before churning permanently.
-
1
Comparing the Two Models: In Iyer and Adamic (2018), we motivated the repeated-usage model through the following assumptions about social product usage:
-
1
Need for social support: A person’s satisfaction with a product experience depends upon how many of their friends are using it.
-
2
Rate-of-usage adjustments: When people gain access to the product, they begin using it at a low rate p0 and then gradually ramp their rate of usage up or down depending upon whether they are satisfied with their experiences.
-
3
Possibility of permanent churn: If people have enough unsatisfying product experiences, they churn permanently and are unwilling to try the product again.
Our threshold model also clearly satisfies the “need for social support” assumption and, like the repeated-usage model, encodes this property through the parameters si. Moreover, the threshold model satisfies the “possibility of permanent churn” assumption. The threshold model does not, however, incorporate gradual “rate-of-usage adjustments” but, rather, binary state changes between adoption and non-adoption. This is in keeping with its being a temporally coarse-grained model of adoption decisions.
In Iyer and Adamic (2018), we also emphasized that the repeated-usage model excludes:
-
1
a budgetary constraint on seeding
-
2
rejection of the seed
-
3
negative word-of-mouth or non-conformism effects
Our threshold model also excludes budgetary constraints, negative word-of-mouth, and non-conformism effects. However, when pa<1, we do allow rejection of the seed. Since there are no negative externalities to adoption in our model, there can be no costs to overambitious seeding if the seeding process is universally successful. We will show, however, that costs naturally emerge if the success of the seeding process is stochastic. Still, there is no direct cost to someone rejecting the seed, so the path to overambitious seeding here is distinct from the one explored, for example, in Abebe et al. (2018).
Comparing the roles of the parameters p0 and pa in the repeated-usage and threshold models respectively, we can refine our fundamental question for each context. In the repeated-usage model, by fixing a low p0, we pose the question: is it optimal to seed everyone at time t=0 if every seeded person adopts, but subsequently uses at a low rate? Meanwhile, by fixing a low pa in the threshold model, we pose the question: is it optimal to seed everyone at time t=0 if seeding succeeds only at a low rate? The simulation results of “Simulation results: cluster-based seeding” and “Simulation results: k-core seeding” sections show that the answer to both of these questions is often “no.”
Toy examples
Before proceeding to the simulation results, we dedicate this section to analytical investigation of our models on certain, very special network structures. These “toy” examples illustrate the mechanisms through which overambitious seeding can reduce long-term adoption. Then, the simulation results of subsequent sections show that these mechanisms are relevant in more general contexts.
Repeated-Usage Model: Suppose we run the repeated-usage model on a network with a very strong core-periphery structure (Borgatti and Everett 2000). In particular, consider a situation where the “core” consists of a complete N-graph (i.e., N people who are all friends with the N−1 others) and the “periphery” consists of N people, each of whom is friends with one person in the core. An example of such a network is shown in Fig. 1a.

a An example of the type of network used in the toy-example calculation for the repeated-usage model, with a complete N-graph for the “core” and N people in the periphery. b An example of the type of network used in the toy-example calculation for the threshold model, with N people each in core, intermediate, and periphery layers. The dark blue line connecting the core indicates that it is a complete N-graph. c Bounds on asymptotic adoption fractions under two seeding strategies in the repeated-usage model. Computations are for a network of the type shown in panel a, but with N=50. d Average steady-state adoption fractions under two seeding strategies in the threshold model. Computations are for a network of the type shown in panel b, but with N=50
As usual in the repeated-usage model, rates of usage pi(t) are initialized to p0 when people receive access. However, for the present purposes, suppose that update rule for pi(t) is a much simpler variant of the one proposed in Eq. (1):
The simplified update rule (2) has certain important corrollaries:
-
1
Satisfaction is reciprocal: Because everyone only needs one active friend to be satisfied (i.e., to raise their rate of usage to 1), if a person i is satisfied with a product experience, then so are all of i’s active friends.
-
2
The state where pi(t)=1is permanent: This follows from item 1, because any i with pi(t)=1 has at least one friend j with pj(t)=1. This implies that all of i’s subsequent product experiences will be satisfying.
-
3
Churn is only possible on the first product experience: This follows from item 2, because if a person i does not churn on the first product experience, then that person ends up in the state where pi(t)=1.
When coupled with the special network structure of Fig. 1a, there is another important implication: once one person in the core has had a satisfying experience, then everyone who is subsequently active in the core will be satisfied.
We now consider the case where we only give access to the core at time t=0. The probability that at least two people are active in the core in the first time step is:
If this occurs, then all of the active people will be satisfied with their experience and update their rates of usage to 1. Then, in the ensuing time steps, others in the core will try out the product, have satisfying experiences, and update their rates of usage to 1 as well. This process will take some time, since each person’s initial choice to be active is independent and will take \(\frac {1}{p_{0}}\) time steps on average. However, if we wait until everyone in the core is consistently active, we can then grant access to the periphery in circumstances where all people in the periphery are guaranteed to have satisfying experiences. Thus, Eq. (3) is a lower bound on the probability with which we can end up with all 2N people adopting. This actually gives a very conservative underestimate of the average adoption fractionFootnote 3, but the bound implied by Eq. (3) is sufficient to demonstrate our main point.
To see why, let us now consider the case where we grant access to everyone at time t=0. Here, we can lower bound the probability that a person i in the periphery will churn. In particular, we can bound it by the sum over all times T of the probability that i is first active in time step T and that i’s friend in the core is not active at all up to and including time step TFootnote 4. This gives:
Then, we can upper bound the average long-term adoption fraction by assuming that everyone except this fraction adopts:
We compare Eqs. (3) to (5) in Fig. 1c. This shows that a lower bound on the adoption under seeding the core beats an upper bound on the adoption under seeding everyone over a broad range of values of p0. The reasoning above exposes why this is the case: by granting access to the periphery too early, we expose people in the periphery to the product before they are likely to be satisfied with their product experiences. Furthermore, except at very low p0, this premature exposure of the periphery confers little benefit to the core, which is sufficiently dense to produce satisfying experiences all on its own. It is better to wait until the core is activated and only then to grant access to the periphery.
Threshold Model with Churn: Next, we consider running our threshold model on the network shown in Fig. 1b. This is a network with a dense “core” of N people who are all connected to one another and who are represented by the blue nodes. There is an “intermediate” layer of N people who are each friends with two randomly chosen people in the core; the people in this “intermediate” layer are represented by the green nodes. Finally, there is a “periphery” of N people who are friends with two randomly chosen people in the intermediate layer and who are represented by red nodes. We will consider a case where si=2 for all people in the network and where pa can vary. We will then ask whether it is better, in terms of asymptotic adoption, to seed everyone or to only seed the core.
First, we consider the case where we only seed the core. The probability that fewer than two people in the core adopt under seeding is given by:
With this probability, adoption dies out completely. On the other hand, if at least 2 people adopt under seeding, then by time t=1, the entire core will adopt. Potentially, some people in the intermediate layer will as well, if they happen to have two friends in the core who adopted during the seeding round. By time t=2, the entire intermediate layer will adopt, because every person in the intermediate layer has two adopting friends in the universally adopting core. Potentially, some people in the periphery will adopt as well, if they happen to have two intermediate layer friends who adopted by time t=1. Finally, by time t=3, the entire periphery will adopt as well, because every person in the periphery has two adopting friends in the universally adopting intermediate layer. Thus, as long as two people in the core adopt during the seeding round, the entire network eventually adopts. This means that the average final adoption fraction is:
Next, we turn to the case where we seed everyone. The probability that at least two people in the core adopt under seeding remains the same. If that happens, then no one in the intermediate layer will churn, including those who happened to adopt under seeding. This is because, as of the adoptions that occur at t=1, every person in the intermediate layer will have 2 adopting friends in the core. However, people in the periphery who adopt under seeding can churn. For a t=0 adopter in the periphery to not churn, one of the following must be true by the first churn round:
-
1
Their two friends in the intermediate layer adopted under seeding.
-
2
One of their friends in the intermediate layer adopted under seeding, and the other had two friends in the core who adopted under seeding.
-
3
Neither of their friends in the intermediate layer adopted under seeding, but both had two friends in the core who adopted under seeding.
In principle, in case 3, the four friends-of-friends in the core need not all be distinct; however, as N grows very large, we can ignore this possibility. Then, the probability that a person in the periphery churns is approximately:
Hence, in the case where at least two people in the core adopt upon seeding, we can expect the final fraction of adopters to approximately be:
When fewer than two people in the core adopt upon seeding everyone, it is still possible for long-term adoption to be sustained if sufficiently many people adopt in the intermediate and periphery layers. This exemplifies how seeding everyone can sometimes be beneficial, especially at small values of pa. Nevertheless, when \(p_{a} >> \frac {2}{N}\), Eq. (9) will still be a good approximation to the average adoptionFootnote 5. We compare Eqs. (7) and (9) in Fig. 1d. Here too, we see that it is preferable to seed only the core over a large range of pa. Yet again, the costs of overambitious seeding originate in the premature exposure of the people in the periphery to the product. These people’s abandonment of the product is avoidable under a more conservative seeding strategy that focuses on the densest part of the network.
Comparing Fig. 1d to c, we see that the costs of overambitious seeding are maximized at some intermediate value of pa for the threshold model, while these costs get bigger as p0 gets lower in the repeated-usage model. This is due to pa playing a dual role in the threshold model, determining both the proportion of the population that is exposed early and the average social support that population can expect. We will return to this point in the “Discussion: When is overambitious seeding costly?” section, when we discuss general settings in which overambitious seeding can be especially problematic.
Networks used in simulations
In Iyer and Adamic (2018), to argue that overambitious seeding can be problematic on real-world networks, we ran simulations of the repeated-usage model on portions of the Facebook friendship graph, known as Social Hash (SH) clusters. The SH clustering was originally developed to enable faster data retrieval by physically collocating data for people who communicate frequently. Thus, many (but not all) of a person’s frequently contacted friends belong to the same SH cluster (Shalita et al. 2016; Kabiljo et al. 2017).
This property is well matched to the type of cluster-level approaches that we tested previously (Iyer and Adamic 2018), and the same is true here. Therefore, in this paper as well, we will report simulation results modeled on de-identified SH clusters containing US Facebook users who visited in a 28 day period. When we discuss cluster-based seeding of the repeated-usage model (in the “Simulation results: cluster-based seeding” section), we report data from simulations on SH clusters computed on 2018-04-29. The properties of the SH clusters used in these simulations can be found in Iyer and Adamic (2018). All other simulations were performed on SH clusters computed for active US users who visited in the 28 days leading up to 2019-01-27.
As in Iyer and Adamic (2018), we also select three-cluster networks such that each cluster has average out-of-cluster degree 〈koc〉>=1Footnote 6. Tables 1 and 2 report statistics of the distributions of the within-cluster degree kic and out-of-cluster degree koc for the various SH clusters and three-cluster networks. These tables show that there is considerable structural diversity amongst these clusters and networksFootnote 7.
Figure 2 shows an example of a three-cluster SH network. This is the network qrs from Table 2.

Empirical three-cluster Social-Hash network qrs. See the text of the “Networks used in simulations” section and Tables 1 and 2 for details about the Social-Hash clusters. In each cluster, we highlight one person in red; we color that person’s within-cluster links yellow and out-of-cluster links light blue
Simulation results: cluster-based seeding
Previously (Iyer and Adamic 2018), we demonstrated the costs of overambitious seeding in the repeated-usage model by showing that seeding a single cluster can lead to greater long-term adoption than seeding all three clusters in a variety of SH networks. In this section, we recap the results of Iyer and Adamic (2018) for the repeated-usage model and then move on to show that the same phenomenon can be observed in the threshold model as well, albeit in a quantitatively weaker form.
Repeated-Usage Model: Figure 3 shows simulation results for the repeated-usage model on three-cluster SH networks. These are the three-cluster networks that we introduced in Iyer and Adamic (2018), and they can be distinguished from the newer clusters used in subsequent sections by the use of uppercase letter labels. In these simulations, we fix si=2 for all people, vary p0, and ask which of the following strategies leads to the most long-term adoption:
-
1
Seed the cluster with the highest median within-cluster degrees kic.
Fig. 3 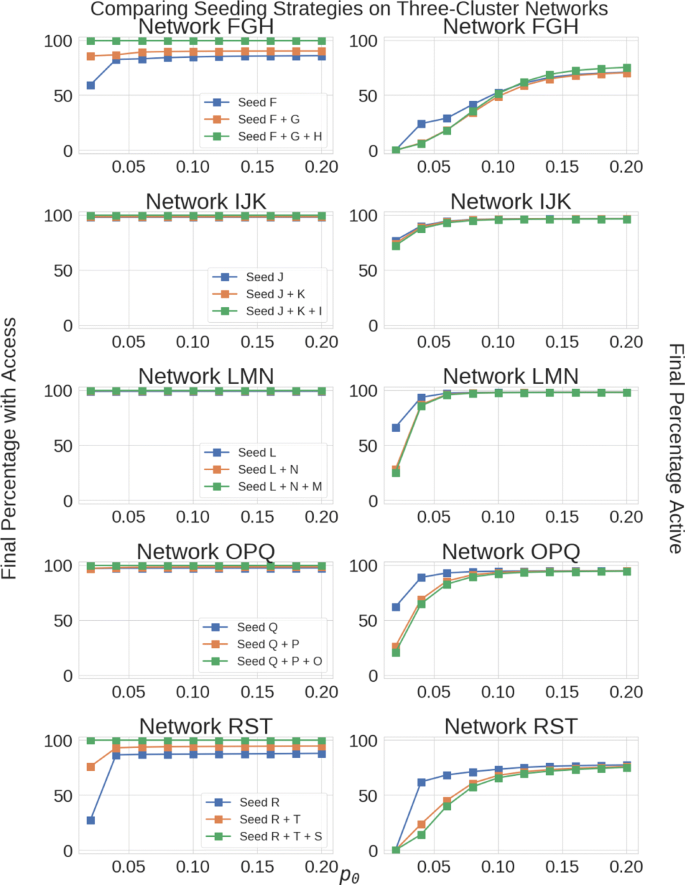
Comparison of cluster-based seeding approaches in the repeated-usage model. Different rows correspond to different three-cluster networks from Table 2 of Iyer and Adamic (2018). The left-hand column shows the average asymptotic percentage of the population with access; the right-hand column shows the average asymptotic percentage that is active. Legends are shared by the left and right panels in each row. The parameters si=2 and δ=0.005 in these simulations. Each data point is an average over 50 simulations. In this and all subsequent plots, we include 95% confidence intervals, but they are sometimes smaller than the plot line
-
2
Seed the two clusters with the highest median within-cluster degrees kic.
-
3
Seed all three clusters.

We report the average adoption in the last 100 time steps of 10000 time step simulations. Simulation results from Iyer and Adamic (2018) showed that 10000 time steps are generally sufficient for adoption to reach its asymptotic value.
The left-hand panels of Fig. 3 show the fraction of the network that has access at late times, and the right-hand panels show the fraction that is active. In these five three-cluster networks, we see that seeding one cluster consistently beats seeding three clusters in the low p0 regime. The “costs” of overambitious seeding here can be substantial: for networks LMN, OPQ, and RST, we observe up to 35-45% less activity under the universal seeding strategy. There is only one network (FGH) where universal seeding at t=0 ever wins, and then only at high p0. Meanwhile, the left-hand panels of Fig. 3 show that, when the single-cluster seeding policies win, it is often despite the fact that there are people who are never given access.
We put forward an argument for why seeding a single-cluster is so often preferable in Iyer and Adamic (2018), which goes as follows: at early times in the repeated-usage model, we are faced with a fundamental tradeoff. There are costs to seeding a cluster, because by assumption, the rate of initial activity p0 is low. Therefore, some people will adopt in unfavorable contexts, meaning that they will typically be unsatisfied by how many of their friends are active when they are. This will result in some permanent churn. On the other hand, there are also costs to not seeding a cluster: in particular, people in other clusters lose out on the social support of people in the unseeded cluster.
In Iyer and Adamic (2018), through simulations on synthetic networks, we demonstrated multiple regimes where this tradeoff plays out in different ways. When p0 is very low, activity is not sustained in the long-term under any seeding strategy. As p0 is tuned up from this regime, we initially enter a regime where the combined early activity in all three clusters is sufficient to sustain long-term activity (i.e., the universal seeding policy wins). At higher values of p0, two clusters can sustain long-term activity in isolation, and it is “costly” in terms of asymptotic activity to seed the third. In other words, seeding the third cluster at time t=0 results in churn that could have been avoided by waiting and granting access to the third cluster under more favorable circumstances, when people in the two seeded clusters are active at very high rates. Finally, if p0 is sufficiently high, a single cluster can sustain long-term activity in isolation, and it is costly to seed any more at t=0.
When studying this model on empirical networks, we typically only observe the final regime, because of the inherent heterogeneity in the within-cluster degree distribution. If we seed a single cluster, there is usually some subnetwork of that cluster (e.g., perhaps involving the highest-degree people) where long-term activity can build up in isolation. Then, the activity in that subnetwork is usually sufficient to bootstrap the spreading of favorable contexts for adoption through the rest of the three-cluster network. Note that the other two regimes (where it is preferable to seed 2 or 3 clusters) presumably still exist; we just do not observe them in Fig. 3 because they occur in a very narrow and low range of p0. Furthermore, idiosyncrasies of graph topologies in empirical networks can produce cases like FGH, where at high p0 we reenter a regime where seeding all three clusters is preferable. Despite these anomalies, seeding one cluster very generally beats seeding three when the repeated-usage model is simulated on real-world networks.
Threshold Model with Churn: In the case of the threshold model, simulations are efficient enough that we can simulate every possible cluster-based seeding strategy for each of the five three-cluster networks. We simulate a case where si=5 for all people. The final adoption curves vs. seed acceptance probability pa are shown in Fig. 4.

Comparison of cluster-based seeding approaches in the threshold model. Different rows correspond to different three-cluster networks from Table 2. The left-hand column shows the final percentage of the network adopting under various cluster-based seeding strategies; the right-hand column shows the difference in the number adopting under seeding the single cluster with the highest median degree vs. all three clusters. The parameter si=5 in these simulations. Each data point is an average over 100 simulations
The clearest case here is network nop. At the lowest values of pa, the strategy of seeding all clusters leads to the highest asymptotic activity. This is for the same reasons that we discussed in the case of the repeated-usage model: there is a tradeoff at early times between exposing people to the product prematurely and missing out on the social support that these people could provide to others. Asymptotic activity first develops when the combined early activity in all three clusters is sufficient to sustain long-term usage. As pa increases though, we observe a small regime (around pa=0.08) where seeding two clusters is optimal. Finally, we enter a regime where seeding just one cluster (cluster p) beats out all other strategies in terms of asymptotic activity.
The other three-cluster networks show similar effects, although the “costs” of overambitious seeding are quantitatively much smaller. For example, in the case of network klm, it is clear that the key ingredient in maximizing long-term adoption is to seed cluster k. Seeding the other clusters is, at best, superfluous throughout the simulated range and incurs some small costs as pa grows. In the cases of networks qrs and wxy, a similar story holds for cluster q and y respectively. For network tuv, seeding either cluster t or cluster u is sufficient, and seeding v is superfluous. In all cases, the zoomed-in views on the right-hand side of Fig. 4 show that, at high pa, a single-cluster-seeding strategy performs best, although as noted above, the “costs” of other seeding strategies are often very small.
Simulation results: k-core seeding
We now turn our attention to a different type of seeding that can lead to better long-term outcomes than universal seeding, even when there is no obvious cluster-structure to leverage. Specifically, we will consider seeding, at t=0, only the k-core of the network under consideration. Here, the k-core is defined as usual: it is the subnetwork that remains after repeatedly removing people with degree less than k and all friendship edges incident to these people. The k-core, if it exists, thus corresponds to a dense subnetwork of the original network. Such a seeding approach has been motivated by much of the argumentation above. In particular, it is motivated by the toy examples for both models, where seeding a dense core of the network can be preferable to seeding the entire network.
Repeated-Usage Model: Figure 5 compares seeding the 10-core of various SH clusters to seeding the entire cluster at time t=0 in the repeated-usage model. As in “Simulation results: cluster-based seeding” section, we set all si=2 here, meaning that everyone needs two active friends to be satisfied during a product experience. We vary p0 and check which strategy (10-core seeding or universal) wins out in the long-time limit. The asymptotic access and activity values plotted in Fig. 5 are again averages over the last 100 time steps of 10000 time-step simulations.

Comparison of 10-core and universal seeding in the repeated-usage model. Different rows correspond to different SH clusters from Table 1. The left-hand column shows the average asymptotic percentage of the population with access; the right-hand column shows the average asymptotic percentage that is active. Legends are shared by the left and right panels in each row. The parameters si=2 and δ=0.005 in these simulations. Each data point is an average over 50 simulations
The simulation results of Fig. 5 show that 10-core seeding leads to more long-term adoption than universal seeding over large ranges of the low p0 regime for five different SH clusters. The costs of universal seeding, as compared to the 10-core strategy, are often very large. Our interpretation of these results, echoing our analysis of the toy examples of the “Toy examples” section, is that it is preferable to allow activity to build up in the core before expanding access to the periphery. This is because people in the core, by virtue of having more friends overall, are much more likely to have satisfying experiences when rates of activity are low. Meanwhile, people in the periphery, because they depend on the usage of a few friends in order to have satisfying experiences, are more likely to have positive product experiences if they receive access after activity has built up in the core.
Threshold Model with Churn: We now study k-core seeding in the threshold model. We will again set si=5 in these simulations, meaning that each person needs five active friends to become or remain active. We will compare the strategy of seeding the 10-core of each SH cluster to seeding the entire cluster.
The simulation results in Fig. 6 generally show three different regimes of behavior. At very low pa, neither approach leads to substantial long-term adoption. As pa grows, there is a regime where universal seeding outperforms 10-core seeding. At still higher pa, 10-core seeding generally wins out. In several cases, 10-core seeding wins by a few percentage points in terms of the total cluster size (clusters a, e, and h). In others, the benefits of 10-core seeding are smaller, but still statistically robust (clusters b, d, f, i, and j).

Comparison of 10-core and universal seeding in the threshold model. Different rows correspond to different SH clusters from Table 1. The left-hand column shows the final percentage of the network adopting under various cluster-based seeding strategies; the right-hand column shows the difference in the number adopting under seeding the 10-core vs. the entire cluster. The parameter si=5 in these simulations. Each data point is an average over 100 simulations
Again, the tradeoff here is similar to what we have observed previously: in the regime where universal seeding outperforms 10-core seeding, the benefits of early activity in the periphery for the core outweigh the costs to the periphery. Generally though, at high enough pa, the tradeoff flips, with the costs to the periphery outweighing benefits to the core. Thus, the more conservative seeding strategy (i.e., 10-core seeding) prevails.
Discussion: When is overambitious seeding costly?
As we noted above in the “Models of social-product usage” section, in the repeated-usage model, the question of overambitious seeding amounts to: is it beneficial to seed everyone if everyone whom you seed will accept, but will use at a low rate? On the other hand, in the threshold model, the question is: is it beneficial to seed everyone if only some of those people will accept? Our simulation results show that the answer to both of these questions can be “no” and that various conservative seeding strategies can do substantially better. In this section, we will attempt to abstract from these observations some general principles around when overambitious seeding should be a cause for concern.
In both cases, context is the key factor in explaining why overambitious seeding is costly. If seeded individuals adopt in contexts where insufficiently many of their friends are adopting or where their friends are not using sufficiently often, they may churn. Meanwhile, if these same individuals are not seeded, better contexts may emerge at later times for them to begin using the product. Thus, one rule-of-thumb for when to worry about overambitious seeding is the following: overambitious seeding can be costly whenever seeding results in contextually-unaware adoption choices (e.g., people adopting uniformly at random, people using at a rate that’s independent of their friends’ rates) but where continued usage crucially depends on context.
Note, however, that the effects of overambitious seeding are much more pronounced in the repeated-usage model than in the threshold model. To understand why this is the case, we should note one important distinction between the parameter pa in the threshold model and the parameter p0 in the repeated-usage model. In the threshold model, the parameter pa influences both whether a person adopts the product at all and how much social support that person can expect at early times. When pa is low, a person can expect little social support, but it is also less likely that it matters, since the person is less likely to adopt in the first place. When pa is higher, a person is more likely to “accept” the product, but is also more likely to experience social contexts that favor continued usage. This restricts the range of pa where overambitious seeding is likely to be relevant. It also restricts the magnitude of the effect because, typically, the people who incur the costs of overambitious seeding are those who adopt during the seeding round (i.e., in a context-unaware way); pa constrains this proportion of the population.
We can contrast this with the role of p0 in the repeated-usage model. Here, p0 determines how much social support a person can expect at early times and also determines the time scale over which a person will choose to have his or her initial product experiences. Meanwhile, this parameter does not determine whether the person has product experiences at all. At low values of p0, a large proportion of people can still end up having bad experiences and churning. Hence, there is both a wider range of p0 where overambitious seeding can be relevant and the proportion of the population that can be “lost” due to a bad seeding strategy is large. This suggests another principle around when we should be especially wary of the costs of overambitious seeding: the problem can be especially severe when people’s initial decisions to adopt the product are less correlated with the amount of social support that they can receive at early times.
It is interesting to also consider recent related work by Sela et al. in this context. These authors study product adoption through an SIR model, where a person adopts (transitioning from the S to the I state) either in a budgeted seeding round or because they subsequently have enough adopting friends. After adopting, a person transitions from the influential (I) to non-influential (R) state after a fixed amount of time. When there is a seeding budget b and people are prioritized for seeding by eigenvector centrality, Sela et al. find that the final adoption rate is non-monotonic in the budget b. They call this phenomenon the “flip anomaly” (Sela et al. 2016). The “flip anomaly” of Sela et al. also admits a contextual explanation along the lines of those that we have proposed above: if a seeded person is the only adopting friend in a non-seeded person’s local network, then the non-seeded person may not adopt before the seeded person becomes non-influential. If better contexts for the non-seeded person’s adoption emerge later on, the now non-influential friend has no opportunity to contribute to that adoption (Sela et al. 2016).
There are two interesting points of comparison between the model of Sela et al. and those that we have studied here. First, Sela et al. note that their “flip anomaly” must reverse as the budget grows, because adoption is universal in their model (Sela et al. 2016). This is also true of other models with similar properties that have recently been reviewed by Centola (2018). Meanwhile, our results show how analogues of the flip anomaly of Sela et al. can still persist with no seeding budget. Indeed, based on the arguments in this paper, we conjecture that the “flip anomaly” would persist in the unbudgeted case of the model of Sela et al. if adoption under seeding was probabilistic rather than universal. A perhaps more interesting distinction is that Sela et al. show how overambitious seeding can be costly even in the absence of churn, because someone in the R state of their SIR model is still interpreted as an adopter. This shows that the “possibility of permanent churn” assumption that we encoded into both of the models studied in this paper is not strictly necessary for overambitious seeding to be a problem. Instead, we can make a more general conjecture: overambitious seeding can be costly whenever it results in premature exhaustion of opportunities for further spreading that would better be delayed to later in the spreading process.
Conclusion
In this paper, we have revisited a question that we originally posed in Iyer and Adamic (2018): suppose a product developer wants to introduce a new social product to a population of potential adopters and is unconstrained by any seeding budget. In this case, should the developer give the product to everyone immediately (as implied by many classic influence-maximization models), or should the developer adopt a more conservative approach?
We have extended the results of Iyer and Adamic (2018) in various ways:
-
1
We have shown that overambitious seeding is not just a concern in the repeated-usage model of Iyer and Adamic (2018) but can be a problem in more traditional threshold models as well, once the possibility of churn is introduced.
-
2
We have studied both types of models analytically on certain simplified network structures and thereby developed intuitions for why overambitious seeding can be costly.
-
3
We have explored k-core seeding as an alternative to cluster-based seeding, showing that the results of our earlier work are not tied to the cluster-based approach; there are multiple conservative seeding strategies that can outperform seeding everyone at once.
Drawing upon simulation results, we have proposed some general principles around when the possibility of overambitious seeding ought to be considered:
-
1
Overambitious seeding is a concern whenever early adoption can result in the premature exhaustion of a resource for future spreading that would be better delayed to a more favorable context for that spreading.
-
2
Overambitious seeding is especially a concern when people’s initial decisions to adopt the product are less correlated with the amount of social support that they can receive at early times.
We emphasize again that the models considered here exclude other pathways to overexposure in the influence maximization problem, including negative word-of-mouth, direct costs to rejection of the seed, and hipster effects. We have excluded these effects to make the case that overambitious seeding can be detrimental in the context of social products, even if none of these factors are at play. Of course, all of these alternative mechanisms are important in real-world settings, and together with the mechanism discussed in this paper, they make the case that product developers should not always expend all of the marketing resources at their disposal.
There are many possible interesting extensions of this work. For example, we have always assumed a homogeneous value of p0 and pa across the whole population of potential adopters. The costs of overambitious seeding will vary if this assumption of homogeneity is relaxed. If people with many friends have higher values of p0 or pa and the friendship network is assortative by degree, presumably seeding everyone would produce an outcome that is more similar to just seeding the core, diminishing the costs of overambitious seeding. On the other hand, if p0 and pa are negatively correlated with degree, that could exacerbate the costs of overambitious seeding and make the considerations of this paper more important.
Another consideration that would mitigate the costs of overambitious seeding in the threshold model would be to allow multiple adoptions per person (i.e., if a person is willing to adopt m times, where m>1). This is because adoptions after the first would happen in contextually aware (and thus, favorable) circumstances, because the person has enough adopting neighbors to adopt. In such a setting, it would be interesting to ask if enriching the model with other aspects of real-world complexity (e.g., some amount of spontaneous churn, some within-person variance over time in social expectations for the product) might reintroduce the costs of overambitious seeding, or fundamentally change the tradeoffs considered here in some unforeseen way.
Here and in Iyer and Adamic (2018), we have always taken the perspective that what matters in influence maximization is adoption in the long-time limit. However, it is possible to consider scenarios where there are time constraints, and the goal is to maximize adoption within a fixed time (Chen et al. 2012). This too could fundamentally change the tradeoffs discussed here, perhaps shifting them in favor of seeding less conservatively.
On the other hand, a very interesting recent line of work in the influence maximization literature considers other target outcomes besides maximum adoption (Matakos and Gionis 2018; Aslay et al. 2018; Tsang et al. 2019; Chen et al. 2019; Pasumarthi et al. 2015; Loukides and Gwadera 2018). As one example, Matakos and Gionis (2018) and Aslay et al. (2018) consider maximizing the diversity of information shared in a social network. Are “overambitious seeding” considerations relevant in such a setting, or is seeding as widely as possible beneficial for promoting diversity? This seems like a fruitful question to pursue, given the findings of this paper for the more traditional influence-maximization problem.
Availability of data and materials
The network datasets used in the simulation studies in this paper are not publicly available. However, the simulation code can be made available upon request.
Notes
If such a mapping holds and the non-progressive model is monotonic, it still may make sense to employ a gradual seeding approach in a budgeted scenario. Indeed, Jankowski et al. have recently explored the benefits of gradually seeding parts of the network that have not been activated by previous seeding rounds, instead of seeding all at once and possibly wasting resources on parts of the network that would have adopted anyway (Jankowski et al. 2017). Note, however, that the notion of “wasting” seeding resources in that work depends upon the existence of a budget.
If it is t=1, then people look at the states of their friends after the seed round.
Because we have not added in possible scenarios where, for instance, no one in the core is active in the first time step but two are active in the second, where one person in the core churns in each of the first two time steps but two people are active in the third, etc. In each of these cases, a very large fraction of the population can nevertheless be active asymptotically.
Here, we are neglecting situations where i’s friend in the core already churned due to having an unsatisfying experience before time T. This is a small effect as N gets large because of the low likelihood of having bad experiences in the core. Meanwhile, it takes each person \(\frac {1}{p_{0}}\) time steps on average to be active at all, so if p0 is small, it is quite likely that a specific individual in the core is inactive at early time T. This is the effect that we capture in Eq. (4).
Note that Eq. (9) is a poor approximation to the adoption fraction when \(p_{a} \approx \frac {2}{N}\) or lower for at least three reasons. First, we need to incorporate corrections to (8) arising from the fact that we condition on at least two people in the core adopting under seeding in that calculation. Second, to produce a good estimate in this regime, we cannot neglect the case of fewer than two core adopters accurately. Third, a good approximation in this regime must approach zero adoption as pa goes to zero; Eq. (9) does not exhibit this behavior.
On average, each person in each cluster has at least one out-of-cluster friend.
Table 1 reports structural properties for 23 SH clusters. Clusters a-j were sampled for the purpose of comparing k-core seeding and universal seeding in the two models. We did not end up reporting results for clusters c and g in Figs. 5 and 6 because these clusters do not have a 10-core, so they are excluded from Table 1. In Fig. 5, we also did not run simulations for clusters b, d, and j because the repeated-usage model is expensive to simulate, and these clusters ended up being too large. Clusters k-y were sampled for the purpose of comparing cluster-based seeding approaches in the threshold-model. These clusters form parts of three-cluster networks whose properties are reported in Table 2. The size of the three-cluster network can differ slightly from the size of the three clusters individually because, in both cases, we exclude people with zero degree, who would inevitably churn under our model. In a small percentage of cases, a person who has no within-cluster friends may still have friends in another cluster when three clusters are considered together.
References
Abebe, R, Adamic LA, Kleinberg JM (2018) Mitigating overexposure in viral marketing In: Proceedings of the 32nd Conference on Artificial Intelligence.. AAAI.
Adler, J (1991) Bootstrap percolation. Phys A Stat Mech Appl 171(3):453–470.
Alkemade, F, Castaldi C (2005) Strategies for the diffusion of innovations on social networks. Comput Econ 25(1-2):3–23.
Anderson, EW (1998) Customer satisfaction and word of mouth. J Serv Res 1(1):5–17.
Aslay, C, Matakos A, Galbrun E, Gionis A (2018) Maximizing the diversity of exposure in a social network In: 2018 IEEE International Conference on Data Mining (ICDM), 863–868.. IEEE.
Banerjee, A, Chandrasekhar AG, Duflo E, Jackson MO (2013) The diffusion of microfinance. Science 341(6144):1236498.
Bass, FM (1969) A new product growth for model consumer durables. Manag Sci 15(5):215–227.
Borgatti, SP, Everett MG (2000) Models of core/periphery structures. Soc Netw 21(4):375–395.
Byers, JW, Mitzenmacher M, Zervas G (2012) The groupon effect on yelp ratings: a root cause analysis In: Proceedings of the 13th ACM Conference on Electronic Commerce, 248–265.. ACM.
Centola, D (2018) How Behavior Spreads: The Science of Complex Contagions, vol. 3. Princeton University Press.
Chen, H, Loukides G, Fan J, Chan H (2019) Limiting the influence to vulnerable users in social networks: A ratio perspective In: International Conference on Advanced Information Networking and Applications, 1106–1122.. Springer.
Chen, W, Lu W, Zhang N (2012) Time-critical influence maximization in social networks with time-delayed diffusion process In: Twenty-Sixth AAAI Conference on Artificial Intelligence.
Coleman, J, Katz E, Menzel H (1957) The diffusion of an innovation among physicians. Sociometry 20(4):253–270.
Coleman, J, Menzel H, Katz E (1959) Social processes in physicians’ adoption of a new drug. J Chronic Dis 9(1):1–19.
Coleman, JS, Katz E, Menzel H (1966) Medical Innovation: A Diffusion Study. Bobbs-Merrill Co.
Cui, F, Hu H-h, Cui W-t, Xie Y (2018) Seeding strategies for new product launch: The role of negative word-of-mouth. PLoS ONE 13(11):0206736.
Domingos, P, Richardson M (2001) Mining the network value of customers In: Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 57–66.. ACM.
Goldenberg, J, Libai B, Muller E (2001) Talk of the network: A complex systems look at the underlying process of word-of-mouth. Mark Lett 12(3):211–223.
Granovetter, M (1978) Threshold models of collective behavior. Am J Sociol 83(6):1420–1443.
Hinz, O, Skiera B, Barrot C, Becker JU (2011) Seeding strategies for viral marketing: An empirical comparison. J Mark 75(6):55–71.
Iyer, S, Adamic LA (2018) The costs of overambitious seeding of social products In: International Workshop on Complex Networks and Their Applications, 273–286.. Springer.
Jankowski, J, Bródka P, Kazienko P, Szymanski BK, Michalski R, Kajdanowicz T (2017) Balancing speed and coverage by sequential seeding in complex networks. Sci Rep 7(1):891.
Juul, JS, Porter MA (2019) Hipsters on networks: How a minority group of individuals can lead to an antiestablishment majority. Phys Rev E 99(2):022313.
Kabiljo, I, Karrer B, Pundir M, Pupyrev S, Shalita A (2017) Social hash partitioner: a scalable distributed hypergraph partitioner. Proc VLDB Endowment 10(11):1418–1429.
Kempe, D, Kleinberg J, Tardos É (2003) Maximizing the spread of influence through a social network In: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 137–146.. ACM.
Kiesling, E, Günther M, Stummer C, Wakolbinger LM (2012) Agent-based simulation of innovation diffusion: a review. CEJOR 20(2):183–230.
Li, Y, Fan J, Wang Y, Tan K-L (2018) Influence maximization on social graphs: A survey. IEEE Trans Knowl Data Eng 30(10):1852–1872.
Loukides, G, Gwadera R (2018) Preventing the diffusion of information to vulnerable users while preserving pagerank. Int J Data Sci Analytics 5(1):19–39.
Matakos, A, Gionis A (2018) Tell me something my friends do not know: Diversity maximization in social networks In: 2018 IEEE International Conference on Data Mining (ICDM), 327–336.. IEEE.
Pasumarthi, R, Narayanam R, Ravindran B (2015) Near optimal strategies for targeted marketing in social networks In: Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, 1679–1680. International Foundation for Autonomous Agents and Multiagent Systems.
Rogers, EM (1962) Diffusion of Innovations. Free Press of Glencoe.
Schelling, TC (2006) Micromotives and Macrobehavior. WW Norton & Company.
Sela, A, Shmueli E, Goldenberg D, Ben-Gal I (2016) Why spending more might get you less, dynamic selection of influencers in social networks In: Science of Electrical Engineering (ICSEE), IEEE International Conference on The, 1–4.. IEEE.
Shalita, A, Karrer B, Kabiljo I, Sharma A, Presta A, Adcock A, Kllapi H, Stumm M (2016) Social hash: An assignment framework for optimizing distributed systems operations on social networks In: NSDI, 455–468.
Tsang, A, Wilder B, Rice E, Tambe M, Zick Y (2019) Group-fairness in influence maximization. arXiv preprint arXiv:1903.00967.
Watts, DJ (2002) A simple model of global cascades on random networks. Proc Natl Acad Sci 99(9):5766–5771.
Wilder, B, Onasch-Vera L, Hudson J, Luna J, Wilson N, Petering R, Woo D, Tambe M, Rice E (2018) End-to-end influence maximization in the field In: Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, 1414–1422.. International Foundation for Autonomous Agents and Multiagent Systems.
Yadav, A, Wilder B, Rice E, Petering R, Craddock J, Yoshioka-Maxwell A, Hemler M, Onasch-Vera L, Tambe M, Woo D (2018) Bridging the gap between theory and practice in influence maximization: Raising awareness about hiv among homeless youth In: IJCAI, 5399–5403.
Acknowledgements
We thank Udi Weinsberg, Israel Nir, and Jarosław Jankowski for helpful discussions, Shuyang Lin for development of the original simulation infrastructure, and Justin Cheng for reviewing code.
Funding
The authors are employed by Facebook and used Facebook computing resources for this research.
Author information
Authors and Affiliations
Contributions
SI formulated the argument for costs of overambitious seeding in the context of the threshold model, developed and ran the simulations, and wrote the manuscript. LAA proposed the repeated-usage model as a setting where the costs of overambitious seeding might be more pronounced and contributed to the composition of Iyer and Adamic (2018). Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Iyer, S., Adamic, L.A. When can overambitious seeding cost you?. Appl Netw Sci 4, 38 (2019). https://doi.org/10.1007/s41109-019-0146-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41109-019-0146-z